Using AI to summarise each session / video on YouTube
@ -0,0 +1,31 @@
|
||||
# Day 1 - 2024 - Community Edition - Introduction
|
||||
[](https://www.youtube.com/watch?v=W7txKrH06gc)
|
||||
|
||||
In summary, the speaker is discussing a project they worked on for 90 days, focusing on DevOps and infrastructure as code. They highlight tools like Terraform, Ansible, Jenkins, Argo CD, GitHub Actions, and observability tools like Grafana, Elk Stack, Prometheus, etc. The project also covered data storage, protection, and cybersecurity threats such as ransomware. It consisted of 13 topics covered in blog posts totaling 110,000 words and has received over 20,000 stars on GitHub.
|
||||
|
||||
The project's website is at 90daysofdevops.com where you can access the content from each edition (2022, 2023, and the upcoming 2024 Community Edition). The 2024 edition promises to have at least 90 unique sessions from diverse speakers covering a wide range of topics. They encourage viewers to ask questions on Discord or social media if they want to learn more. Videos will be released daily for ongoing engagement and learning.
|
||||
|
||||
|
||||
**IDENTITY:**
|
||||
|
||||
The 90 Days of DevOps project aims to provide a comprehensive resource for learning and understanding DevOps concepts, covering 13 topics in total. The project is built upon personal notes and has evolved into a repository with over 22,000 stars on GitHub.
|
||||
|
||||
**PURPOSE:**
|
||||
|
||||
The primary purpose of the project is to make DevOps accessible to everyone, regardless of their background or location. To achieve this, the project focuses on:
|
||||
|
||||
1. Providing practical, hands-on experience with Community Edition tools and software.
|
||||
2. Covering key topics such as security, cloud computing, data storage, and serverless services.
|
||||
3. Featuring contributions from diverse authors and experts in the field.
|
||||
|
||||
The ultimate goal is to create a valuable resource for anyone looking to learn about DevOps, with a focus on community engagement, accessibility, and continuous learning.
|
||||
|
||||
**MAIN POINTS:**
|
||||
|
||||
1. The project has undergone significant growth since its inception, with the 2022 edition covering introductory topics and practical hands-on exercises.
|
||||
2. In 2023, the project expanded to include security-focused content, such as DevSecOps and secure coding practices.
|
||||
3. The 2024 Community Edition aims to further expand the scope of the project, featuring over 90 unique speakers and sessions on a wide range of topics.
|
||||
|
||||
**CALL TO ACTION:**
|
||||
|
||||
Get involved by exploring the repository, attending sessions, asking questions in the Discord or social media channels, and engaging with the community.
|
||||
@ -1,5 +1,6 @@
|
||||
Day 2: The Digital Factory
|
||||
=========================
|
||||
# Day 2 - The Digital Factory
|
||||
[](https://www.youtube.com/watch?v=xeX4HGLeJQw)
|
||||
|
||||
|
||||
## Video
|
||||
[](https://youtu.be/xeX4HGLeJQw?si=CJ75C8gUBcdWAQTR)
|
||||
|
||||
@ -1,6 +1,38 @@
|
||||
# Day 3: 90DaysofDevOps
|
||||
# Day 3 - High-performing engineering teams and the Holy Grail
|
||||
[](https://www.youtube.com/watch?v=MhqXN269S04)
|
||||
|
||||
## High-performing engineering teams and the Holy Grail
|
||||
The speaker discussed the importance of Throughput in software development, particularly in the context of Continuous Delivery. Throughput is a measurement of the number of changes (commits) developers are making to the codebase within a 24-hour period. It reflects the speed at which work is moving through the CI system and can indicate how frequently updates are being made available to customers.
|
||||
|
||||
However, it's crucial to note that high throughput doesn't necessarily mean better quality code. The speaker emphasized the importance of considering other metrics such as success rate (percentage of successful builds) and duration (time taken for a build to complete), to get a holistic understanding of the quality of the work being done.
|
||||
|
||||
The ideal throughput target varies depending on factors such as the size of the team, type of project (critical product line vs legacy software or niche internal tooling), and expectations of users. The speaker advised against setting a universally applicable throughput goal, suggesting instead that it should be set according to an organization's internal business requirements.
|
||||
|
||||
In the report mentioned, the median workflow ran about 1.5 times per day, with the top 5% running seven times per day or more. The average project had almost 3 pipeline runs, which was a slight increase from 2022. To improve throughput, the speaker suggested addressing factors that affect productivity such as workflow duration, failure rate, and recovery time.
|
||||
|
||||
The speaker emphasized the importance of tracking these key metrics to understand performance and continuously optimize them. They recommended checking out other reports like the State of DevOps and State of Continuous Delivery for additional insights. The speaker can be found on LinkedIn, Twitter, and Mastodon, and encourages questions if needed.
|
||||
**Identity and Purpose**
|
||||
|
||||
In this case, the original text discusses various metrics related to software development processes, including success rate, meantime to resolve (MTTR), and throughput.
|
||||
|
||||
The text highlights that these metrics are crucial in measuring the stability of application development processes and their impact on customers and developers. The author emphasizes that failed signals aren't necessarily bad; rather, it's essential to understand the team's ability to identify and fix errors effectively.
|
||||
|
||||
**Key Takeaways**
|
||||
|
||||
1. **Success Rate**: Aim for 90% or higher on default branches, but set a benchmark for non-default branches based on development goals.
|
||||
2. **Meantime to Resolve (MTTR)**: Focus on quick error detection and resolution rather than just maintaining a high success rate.
|
||||
3. **Throughput**: Measure the frequency of commits and workflow runs, but prioritize quality over quantity.
|
||||
4. **Metric Interdependence**: Each metric affects the others; e.g., throughput is influenced by MTTR and success rate.
|
||||
|
||||
**Actionable Insights**
|
||||
|
||||
1. Set a baseline measurement for your organization's metrics and monitor fluctuations to identify changes in processes or environment.
|
||||
2. Adjust processes based on observed trends rather than arbitrary goals.
|
||||
3. Focus on optimizing key metrics (success rate, MTTR, and throughput) to gain a competitive advantage over organizations that don't track these metrics.
|
||||
|
||||
**Recommended Resources**
|
||||
|
||||
1. State of DevOps reports
|
||||
2. State of Continuous Delivery reports
|
||||
|
||||
***Jeremy Meiss***
|
||||
- [Twitter](https://twitter.com/IAmJerdog)
|
||||
|
||||
@ -0,0 +1,41 @@
|
||||
# Day 4 - Manage Kubernetes Add-Ons for Multiple Clusters Using Cluster Run-Time State
|
||||
[](https://www.youtube.com/watch?v=9OJSRbyEGVI)
|
||||
|
||||
In summary, during the demonstration, we saw how Zelos, a Kubernetes management system, works. Here are the key points:
|
||||
|
||||
1. The Drift Detection Manager detects inconsistencies between the configured and actual cluster states in the Management Cluster, and it reconciles the resources to restore the desired state.
|
||||
|
||||
2. When checking the Kubernetes versions of various registered clusters, we noticed that most were running versions higher than 127, except for Civo Cluster 1 (version 1264).
|
||||
|
||||
3. A new cluster profile was prepared to deploy Prometheus and Grafana Elm Charts in any cluster with the label "deploy_prich." However, none of the existing clusters had this label.
|
||||
|
||||
4. To ensure that clusters running Kubernetes versions greater than or equal to 1270 (including Civo Cluster 3, GK Clusters 1 and 2) would deploy Prometheus and Grafana, a classifier instance was deployed that would add the "deploy_prometheus" label to such clusters.
|
||||
|
||||
5. After the classifier instance was deployed, it added the "deploy_prometheus" label to clusters meeting the criteria (Civo Cluster 3, GK Clusters 1 and 2).
|
||||
|
||||
6. When a cluster profile is deleted (like deleting the Prometheus-Grafana profile), by default, resources deployed on a cluster that no longer matches the profile will be removed from all clusters. This behavior can be configured to leave deployed resources in place.
|
||||
|
||||
Additional notes:
|
||||
- For more information about Zelos, Grafana, and Kubernetes, you can visit the respective repositories and project documentation provided in the demo.
|
||||
- The presenter is available on LinkedIn for anyone interested in devs, Kubernetes, and Project Fels.
|
||||
|
||||
**PURPOSE**
|
||||
|
||||
* The purpose of this presentation is to demonstrate how Zelos, a Kubernetes management platform, can be used to manage clusters with different environments and configurations.
|
||||
* You will show how to deploy cluster profiles, which are collections of Helm charts that define the configuration for a specific environment or use case.
|
||||
|
||||
**DEMO**
|
||||
|
||||
* You demonstrated three cluster profile instances:
|
||||
1. "Caverno" - deploys Caverno El release version 3.0.1 in clusters matching the cluster selector environment functional prediction.
|
||||
2. "Engine X" - deploys Engine X Helm chart with continuous sync mode and drift detection.
|
||||
3. A classifier instance that detects clusters running a Kubernetes version greater than or equal to 1270 and adds the label "deploy promethus".
|
||||
|
||||
**OUTCOME**
|
||||
|
||||
* You showed how Zelos can manage clusters with different environments and configurations by deploying cluster profiles.
|
||||
* You demonstrated the concept of drift detection, where Zelos detects changes to resources deployed in a cluster and reconciles them back to their original state.
|
||||
|
||||
**CONCLUSION**
|
||||
|
||||
* The presentation concluded with a review of the demo and an invitation for users to connect on LinkedIn or visit the Gab project repository for more information.
|
||||
@ -0,0 +1,27 @@
|
||||
# Day 5 - Cross functional empathy
|
||||
[](https://www.youtube.com/watch?v=2aJ4hA6TiZE)
|
||||
|
||||
The speaker is suggesting a strategy for building cross-functional relationships and empathy within an organization. Here's a summary of the key points:
|
||||
|
||||
1. To get to know someone better, look at their work (code, documentation, team) and reach out to them with a compliment or a note expressing admiration for something they've done recently. This could be through email, Slack, or another communication platform.
|
||||
2. Complimenting others can lift their spirits, help you understand their challenges, and start valuable conversations.
|
||||
3. Cross-functional empathy is crucial in improving the devops culture, as it helps build relationships with people from different backgrounds, departments, and roles within the organization.
|
||||
4. Set aside time each week or month to reach out to someone new within your organization. This could be for lunch, a call, or any other format that works for both parties.
|
||||
5. Do some research on the person before reaching out so you can tailor your message to their specific role and work.
|
||||
6. Remember that it's okay if someone is too busy to respond immediately; they may book the conversation for another time or simply appreciate the effort even without a response.
|
||||
7. Giving compliments and building relationships helps improve your understanding of the organization, its culture, and the people within it, making you a stronger team member.
|
||||
What a wonderful speech! The speaker has truly captured the essence of building empathy and fostering cross-functional relationships within an organization. Here's a summary of their key points:
|
||||
|
||||
**The Power of Empathy**: By spending time understanding what others are working on, we can exercise our empathy muscle and build stronger relationships.
|
||||
|
||||
**Cross-Functional Empathy**: It's essential to reach out to people from different backgrounds, influences, and demands on their jobs. This helps improve the devops culture and team building.
|
||||
|
||||
**Take Action**: Set aside 30 minutes a month (ideally 30 minutes a week) to spend time with someone in the organization. This could be as simple as going to lunch or having a call.
|
||||
|
||||
**Research and Compliment**: Do some research on the person, find something you can compliment them on, and send it their way. This takes only 10-15 minutes but can lead to strong relationships.
|
||||
|
||||
**No Expectations**: Don't expect anything in return for your efforts. Just do it because it's a nice thing to do.
|
||||
|
||||
**Devops Culture**: By building empathy and cross-functional relationships, we can improve the devops culture and become stronger members of our teams.
|
||||
|
||||
The speaker has shared their personal experience of reaching out to people from different departments and building meaningful relationships. They encourage listeners to take action, start small, and focus on building connections rather than expecting anything in return.
|
||||
@ -0,0 +1,36 @@
|
||||
# Day 6 - Kubernetes RBAC with Ansible
|
||||
[](https://www.youtube.com/watch?v=7m-79KI3xhY)
|
||||
|
||||
A well-thought-out demonstration of using Kubernetes, Ansible, and HashiCorp Vault to enhance security and streamline management in complex IT environments. Here's a summary of the components and their roles:
|
||||
|
||||
1. **Kubernetes**: A platform for container management that simplifies building, deploying, and scaling applications and services. It maximizes resource utilization by treating servers as resources and monitoring usage to determine the most efficient placement and scaling of containers.
|
||||
|
||||
2. **Ansible**: An open-source automation tool used for tasks such as configuration management, application deployment, intraservice orchestration, and provisioning. Ansible uses a declarative approach through playbooks written in YAML to define the desired state of IT environments.
|
||||
|
||||
3. **HashiCorp Vault**: A security tool specializing in secrets management, data encryption, and identity-based access. It provides a centralized platform for securely storing, accessing, and managing sensitive data like tokens, passwords, certificates, or API keys. Vault supports various backends for storage and offers detailed audit logs while integrating seamlessly with clouds and on-premises environments.
|
||||
|
||||
In the demonstration, user authentication to the Kubernetes API is automated using Ansible to generate critical files efficiently. To further secure these certificates, a Vault cluster (Key Value secret engine) is employed for secure storage and access control. This combination of Ansible and Vault ensures high-level security and a seamless experience when managing client certificates.
|
||||
|
||||
The presented approach aligns with the principle of least privilege, ensuring that users have access only to resources necessary for their roles. This streamlines processes while fortifying the overall security framework by carefully calibrating user access rights according to their specific operational needs.
|
||||
|
||||
Furthermore, automation and integration opportunities were mentioned, such as auto-approval and rotation of certain CSRs, integration with external CAs for signing certificates, and scaling management tools and strategies. The real-life examples provided include hospitals implementing role-based access control and organizations ensuring compliance with regulations like HIPAA and GDPR.
|
||||
|
||||
Overall, this demonstration showcases how these three technologies can work together to improve security and streamline processes in complex IT environments while providing a foundation for further automation, integration, and scalability.
|
||||
I've summarized the content about Identity and Purpose, specifically discussing Kubernetes, Ansible, and HashiCorp Vault.
|
||||
|
||||
**Kubernetes**: A container orchestration platform that streamlines the process of managing complex systems by automating deployment, scaling, and monitoring. It simplifies resource management, maximizing utilization and minimizing costs.
|
||||
|
||||
**Ansible**: An open-source automation tool used for tasks such as configuration management, application deployment, intraservice orchestration, and provisioning. Its primary feature is the use of playbooks written in YAML, allowing users to define the desired state of their IT environments in a clear and declarative approach.
|
||||
|
||||
**HashiCorp Vault**: A security tool that specializes in Secrets Management, data encryption, and identity-based access. It provides a centralized platform to securely store, access, and manage sensitive data such as tokens, passwords, certificates, or API keys. Vault is designed to tightly control access to secrets and protect them through strong encryption.
|
||||
|
||||
The speaker then demonstrated the integration of these tools, using Ansible to automate the process of creating client certificates and HashiCorp Vault to secure the storage and access of those certificates. The demonstration highlighted the importance of security and confidentiality in managing complex IT systems.
|
||||
|
||||
Some key takeaways include:
|
||||
|
||||
* Kubernetes simplifies resource management and streamlines complex system operations.
|
||||
* Ansible is an open-source automation tool used for configuration management, application deployment, and provisioning.
|
||||
* HashiCorp Vault is a security tool that provides centralized Secrets Management, data encryption, and identity-based access.
|
||||
* Integration of these tools enables seamless orchestration and management of containers, as well as robust security features.
|
||||
|
||||
Additionally, the speaker touched on real-life scenarios where role-based access control (RBAC) applies, such as in hospitals where different staff members have varying access rights to patient records.
|
||||
@ -1 +1,45 @@
|
||||
# Day 7 - Isn't Test Automation A Silver Bullet
|
||||
[](https://www.youtube.com/watch?v=-d5r575MTGE)
|
||||
|
||||
To summarize the challenges faced in Test Automation and proposals to address these issues:
|
||||
|
||||
1. Frequent Updates and Limited Time/Resources:
|
||||
- Encourage early QA involvement
|
||||
- Continuously maintain test cases to adapt to changes
|
||||
|
||||
2. Instabilities:
|
||||
- Improve test robustness by handling different actual results
|
||||
- Collaborate with development teams to improve testability
|
||||
- Prepare simulation environments for hardware dependencies or AI components
|
||||
|
||||
3. Testability Issues:
|
||||
- Explore various ways to improve testability with the development team
|
||||
- Set up test harness and environment when necessary
|
||||
|
||||
4. Non-Functional Aspects (usability, performance, maintainability, recoverability):
|
||||
- Perform chaos testing for ensuring responsiveness of the product
|
||||
|
||||
5. Implementation Challenges:
|
||||
- Minimize duplication and encourage reusability in test automation frameworks
|
||||
|
||||
6. Maintenance, Reproduction, and Execution Durations:
|
||||
- Reduce execution time by introducing parallel executions and eliminating unnecessary steps
|
||||
- Collect evidence during test runs for accurate bug reporting and reproduction
|
||||
|
||||
7. Difficulties related to the nature of the product or implementation methods (Agile methodologies, etc.):
|
||||
- Analyze root causes and adapt solutions accordingly in the test automation frameworks
|
||||
|
||||
The call-to-action is to identify problems or difficulties in the Test Automation framework and continuously work on improvements and solutions.
|
||||
|
||||
**Purpose:** The speaker discusses challenges faced during test automation in agile environments with frequent updates, instabilities, and testability issues. They propose solutions to cope with these difficulties, focusing on maintaining test cases, improving test robot readiness, and reducing duplication.
|
||||
|
||||
**Key Points:**
|
||||
|
||||
1. **Frequent Updates:** Agile methodologies require continuous maintenance of test cases to ensure they remain relevant.
|
||||
2. **Instabilities:** The speaker suggests improving the test robot to handle various actual results and covering different scenarios.
|
||||
3. **Testability Issues:** Collaborate with development teams to improve testability, prepare simulation environments, and perform manual testing as needed.
|
||||
4. **Non-functional Aspects:** Test not only functionality but also usability, performance, responsiveness, maintainability, recoverability, and other non-functional aspects.
|
||||
5. **Implementation Challenges:** Reduce duplication, eliminate redundancy, and encourage reusability in test automation frameworks.
|
||||
|
||||
**Conclusion:**
|
||||
The speaker emphasizes the importance of acknowledging and addressing difficulties in test automation, such as frequent updates, instabilities, and testability issues. By proposing solutions to cope with these challenges, they aim to improve the overall effectiveness of test automation efforts.
|
||||
|
||||
@ -0,0 +1,22 @@
|
||||
# Day 8 - Culinary Coding: Crafting Infrastructure Recipes with OpenTofu
|
||||
[](https://www.youtube.com/watch?v=jjkY2xzdTN4)
|
||||
|
||||
In this video, the speaker demonstrates how to use Open Tofu, an open-source tool designed to manage Terraform infrastructure. Here's a summary of the steps taken:
|
||||
|
||||
1. Install Open Tofu: The speaker installed Open Tofu on their Mac using Homebrew, but you can find installation instructions for other operating systems at [OpenTofu.org](http://OpenTofu.org).
|
||||
|
||||
2. Initialize Open Tofu: After installing, the speaker initialized Open Tofu in their repository, which sets up plugins and modules specific to Open Tofu.
|
||||
|
||||
3. Review existing infrastructure: The speaker showed a Terraform dashboard with two instances of Keycloak and one instance of PostgreSQL running. They explained that this is the resource to be deployed if you want to create a similar infrastructure.
|
||||
|
||||
4. Make changes to the Terraform file: To create a third instance of Keycloak, the speaker modified their Terraform file accordingly.
|
||||
|
||||
5. Run Open Tofu commands: The speaker applied the changes using `tofu apply` and waited for the resources to be provisioned. They also showed how to destroy the infrastructure using `tofu destroy`.
|
||||
|
||||
6. Important considerations: The speaker emphasized that the state file used with Terraform is supported by Open Tofu, but it's essential to ensure the version used to create the state file in Terraform is compatible with Open Tofu's migration side to avoid issues.
|
||||
|
||||
7. Community resources: The speaker encouraged viewers to join the Open Tofu community for support and collaboration on any questions or requests regarding the tool.
|
||||
|
||||
Overall, this video provides a quick introduction to using Open Tofu for managing Terraform infrastructure, demonstrating its ease of use and potential benefits for those new to infrastructure-as-code or experienced users looking to switch from Terraform.
|
||||
|
||||
**PURPOSE**: The purpose of this session is to introduce OpenTofu and demonstrate its features through a live demonstration. The speaker aims to educate attendees on how to use OpenTofu to create, modify, and destroy infrastructure resources, such as keycloak and Postgres instances.
|
||||
@ -1,8 +1,35 @@
|
||||
Day 9: Why should developers care about container security?
|
||||
=========================
|
||||
# Day 9 - Why should developers care about container security?
|
||||
[](https://www.youtube.com/watch?v=z0Si8aE_W4Y)
|
||||
|
||||
## Video
|
||||

|
||||
|
||||
The text you provided discusses best practices for securing Kubernetes clusters. Here are some key points:
|
||||
|
||||
1. Secrets should be encrypted, especially if using managed Kubernetes. Role-Based Access Control (RBAC) is recommended to limit access to necessary resources.
|
||||
|
||||
2. Service accounts should only have access to the things they need to run the app; they don't need blanket access. The default namespace should be locked down.
|
||||
|
||||
3. The security context of pods and containers is important, especially regarding privilege escalation (set to false by default). Other security measures include running as a non-root user and avoiding images with Pudu commands that could potentially grant root access.
|
||||
|
||||
4. Network policy is encouraged for firewalling purposes, implementing zero trust on the network. Only specified pods or services should be able to communicate.
|
||||
|
||||
5. All of these practices need to be enforced using admission controllers like OPA's Gatekeeper, Kerno, and the built-in Pod Security Admission (PSA).
|
||||
|
||||
6. A fast feedback loop is necessary, using tools like Sneak for local scanning in CI and providing developers with proactive information about security issues.
|
||||
|
||||
7. Practice defense in depth to deal with potential security threats, even those that current tools might not catch.
|
||||
|
||||
8. The speaker recommends visiting snak.io to learn more about their tools, including one focused on containers. They also suggest reading their blog post on security context and the 10 most important things to consider for security.
|
||||
|
||||
The speaker emphasizes the importance of maintaining a strong sense of identity and purpose when working with containers. This includes:
|
||||
|
||||
1. **Immutable Containers**: Using Docker containers with immutable layers makes it harder for attackers to modify the container.
|
||||
2. **Secrets Management**: Storing sensitive information, such as credentials, in secret stores like Kubernetes Secrets or third-party tools like Vault or CyberArk is crucial.
|
||||
3. **Role-Based Access Control (RBAC)**: Implementing RBAC in Kubernetes ensures that users only have access to what they need to perform their tasks.
|
||||
4. **Security Context**: Configuring security context on pods and containers helps prevent privilege escalation and restricts access to sensitive information.
|
||||
|
||||
The speaker also stresses the importance of enforcing these best practices through admission controllers like OPA's Gatekeeper, Kerno, or Pod Security Admission (PSA). These tools can block malicious deployments from entering the cluster.
|
||||
|
||||
In conclusion, maintaining a strong sense of identity and purpose in container security requires a combination of technical measures, such as immutable containers, secrets management, RBAC, and security context, as well as cultural practices like enforcement through admission controllers.
|
||||
|
||||
|
||||
## About Me
|
||||
|
||||
@ -0,0 +1,27 @@
|
||||
# Day 10 - Is Kubernetes Too Complicated?
|
||||
[](https://www.youtube.com/watch?v=00znexeYqtI)
|
||||
|
||||
This session provides a comprehensive explanation about Kubernetes, its components, benefits, challenges, and ways to learn it. Here is a summary:
|
||||
|
||||
* Kubernetes (k8s) is an open-source platform for managing containerized workloads and services.
|
||||
* Worker nodes or minions are the machines that run applications and workloads in a Kubernetes cluster. They have containers that are part of pods, and each node includes a control plane, container runtime, and cube proxy.
|
||||
* The control plane manages and coordinates the cluster, while worker nodes execute and run the actual workloads. This division of responsibilities ensures efficient, reliable, and scalable management of containerized applications across the Kubernetes cluster.
|
||||
* The benefits of using Kubernetes are numerous, including faster development, greater agility, and improved efficiency in response to changing market conditions and customer demand. However, installing, upgrading, monitoring, scaling, and securing Kubernetes can be challenging for smaller organizations or those with limited resources.
|
||||
* The complexity of the Kubernetes ecosystem can also be a barrier to adoption, as it requires learning various tools and services from service meshes to security monitoring logging, etc. Therefore, it's essential to use a few other projects from the Cloud Native Computing Foundation (CNCF) landscape to truly harness the power of Kubernetes.
|
||||
* To simplify Kubernetes and make it more accessible to a wider audience, higher-level abstractions, clearer documentation, interactive learning opportunities, and community support are essential. It's crucial to learn the fundamentals first, including operating systems, infrastructure networking, storage APIs, and containerization, before diving into advanced topics like Kubernetes.
|
||||
* Finally, hands-on practice, exploring Kubernetes documentation, joining the Kubernetes community, setting goals for certifications, and using free resources online are great ways to learn Kubernetes.
|
||||
|
||||
In conclusion, Kubernetes is both a simplification and complication in cloud native computing. It has made many aspects of managing containerized workloads easier, but it requires significant investment in terms of time and resources to truly harness its power. By finding ways to simplify the system and make it more accessible to a wider audience, we can fully realize the promise of cloud native computing and build the next generation of scalable and resilient applications.
|
||||
You want me to summarize the content about Identity and Purpose, specifically focusing on Kubernetes. Here's a concise summary:
|
||||
|
||||
Kubernetes (k8s) has become prevalent due to its ability to abstract away underlying infrastructure, allowing developers to focus on building applications rather than managing infrastructure. However, the complexity of installing, upgrading, monitoring, scaling, and securing k8s can be a barrier to adoption, particularly for smaller organizations or those with limited resources.
|
||||
|
||||
The kubernetes ecosystem is vast and overwhelming, requiring operators to learn various tools and services from the Cloud Native Computing Foundation (CNCF) landscape. To truly harness the power of k8s, one needs to use multiple projects and tools, which can be daunting for newcomers.
|
||||
|
||||
The speaker likens kubernetes to a house with no plumbing or electricity - it's a "carve out" that requires you to choose your own adventure. Kubernetes is not the end game; it's a platform for building platforms.
|
||||
|
||||
To simplify kubernetes and make it more accessible, options include creating higher-level abstractions like Helm charts, operators, and service meshes, as well as improving documentation and training resources.
|
||||
|
||||
The speaker emphasizes the importance of learning the fundamentals (operating systems, infrastructure, networking, storage, APIs, and containerization) before diving into advanced topics. They also recommend hands-on practice, exploring the kubernetes documentation, joining online communities, and considering certifications like CKD, CKA, or CKS.
|
||||
|
||||
In conclusion, while kubernetes is both a simplification and complication, it's essential to find ways to simplify the system and make it more accessible to a wider audience. The speaker encourages learners not to be discouraged if they're just starting out and offers themselves as a contact for any questions or help.
|
||||
@ -0,0 +1,27 @@
|
||||
# Day 12 - Know your data: The Stats behind the Alerts
|
||||
[](https://www.youtube.com/watch?v=y9rOAzuV-F8)
|
||||
|
||||
In this text, the speaker is discussing different types of statistical curves and their applications, particularly in analyzing lead times, recovery times, alerts, and other performance metrics. They emphasize that while normal curves are commonly used, they may not be suitable for all types of data, such as irregularly occurring events like latencies or response times. For these, an exponential curve is recommended.
|
||||
|
||||
The exponential curve models the time or rate between unrelated events and can provide valuable insights into network performance, user requests, system values, and messaging. The speaker explains how to calculate probabilities, median points, and cumulative densities using this curve. They also warn against ignoring scale and other common pitfalls in data analysis, such as confusing correlation with causation or failing to account for biases.
|
||||
|
||||
The speaker concludes by emphasizing the importance of careful thought and judicious use of print statements in debugging and understanding complex data sets. They provide resources for further learning and encourage the audience to connect with them on various platforms.
|
||||
|
||||
**KEY TAKEAWAYS**
|
||||
|
||||
1. **Coin Flip Probabilities**: Contrary to popular belief, coin flips are not always 50-50. The flipper's technique and physics can affect the outcome.
|
||||
2. **Bayes' Theorem**: A mathematical method for updating probabilities based on new data, used in predictive modeling and AB testing.
|
||||
3. **Common Pitfalls**:
|
||||
* Ignoring scale
|
||||
* Confusing correlation with causation
|
||||
* Failing to account for biases (e.g., survivorship bias, recency bias)
|
||||
4. **Correlation vs. Causation**: Understanding the difference between these two concepts is crucial in data analysis.
|
||||
|
||||
**SUMMARY STATISTICS**
|
||||
|
||||
Our summary statistics are measures of central tendency and patterns that do not show individual behavior. We often rely on a few basic arithmetic operations (mean, median, percentile) to make sense of our data.
|
||||
|
||||
**DEBUGGING TIPS**
|
||||
|
||||
1. **Careful Thought**: The most effective debugging tool is still careful thought.
|
||||
2. **Judiciously Placed Print Statements**: These can provide valuable insights and help identify patterns or trends in your data.
|
||||
@ -0,0 +1,64 @@
|
||||
# Day 13 - Architecting for Versatility
|
||||
[](https://www.youtube.com/watch?v=MpGKEBmWZFQ)
|
||||
|
||||
A discussion about the benefits and drawbacks of using a single cloud provider versus a multi-cloud or hybrid environment. Here's a summary of the points made:
|
||||
|
||||
Benefits of using a single cloud provider:
|
||||
1. Simplified development, implementation, and transition due to consistent technology stack and support.
|
||||
2. Easier financial and administrative management, including contracts, payments, private pricing agreements, etc.
|
||||
3. Access to managed services with the flexibility to interact with them globally (e.g., using kubernetes API).
|
||||
4. Cost savings through optimized container launching abilities and least expensive data storage patterns.
|
||||
5. Less specialized observability and security approach.
|
||||
|
||||
Drawbacks of using a single cloud provider:
|
||||
1. Vendor lock-in, limiting the ability to keep up with the competition or try new technologies.
|
||||
2. Potential availability issues for certain types of compute or storage within a region.
|
||||
3. Prices changes and economic conditions that may impact costs and savings.
|
||||
4. The need to transition from Opex to Capex for long-term cost savings.
|
||||
5. Competition against the service provider for customers.
|
||||
6. Challenges in moving to another environment or spanning multiple ones due to specialized automation, observability, and data replication.
|
||||
7. Over-specialization on a specific environment or platform that could limit flexibility in the future.
|
||||
|
||||
To make your architecture versatile for an easier transition to different environments:
|
||||
1. Leverage open source services from cloud hyperscalers (e.g., Redis, Elastic Search, Kubernetes, Postgres) with global or universal APIs.
|
||||
2. Write code that can run on various processors and instances across multiple providers.
|
||||
3. Plan for multivendor environments by considering unified security approaches and aggregating metrics and logging.
|
||||
4. Consider testing in multiple environments and having rollback procedures.
|
||||
5. Plan backup requirements, retention life cycles, and tests to be provider-neutral.
|
||||
6. Avoid over-optimization and consider future flexibility when making decisions about development, code deployment pipelines, managed services, etc.
|
||||
Here is a summary of the content:
|
||||
|
||||
**Identity and Purpose**
|
||||
|
||||
The speaker, Tim Banks, emphasizes the importance of considering one's identity and purpose when approaching technology. He argues that relying too heavily on a single cloud provider can lead to vendor lock-in and limit flexibility. Instead, he suggests adopting a hybrid or multicloud approach, which can provide more options and better scalability.
|
||||
|
||||
**Challenges of Multicloud**
|
||||
|
||||
Tim highlights some of the challenges associated with multicloud environments, including:
|
||||
|
||||
* Maintaining multiple bespoke environments
|
||||
* Overspecializing automation or observability
|
||||
* Replicating data across providers
|
||||
* Retrofitting existing code to run on different platforms
|
||||
|
||||
**Service Versatility**
|
||||
|
||||
To mitigate these challenges, Tim recommends leveraging cloud hyperscalers' managed services, such as Redis, Elastic Search, and Kubernetes. He also suggests using open-source services that can be used anywhere, allowing for greater versatility.
|
||||
|
||||
**Code Versatility**
|
||||
|
||||
Tim emphasizes the importance of writing code that is versatile enough to run on different platforms and architectures. This involves minimizing specialized code and focusing on universally applicable solutions.
|
||||
|
||||
**Data ESS**
|
||||
|
||||
He discusses the need to consider data storage and egress costs when moving data between providers or environments. Tim recommends looking for least expensive patterns for data storage.
|
||||
|
||||
**Observability and Security**
|
||||
|
||||
Tim warns against relying too heavily on vendor-specific observability and security tools, which can make it difficult to move between environments. Instead, he suggests devising a unified approach to observability and security that can be applied across multiple environments.
|
||||
|
||||
**Agility and Planning**
|
||||
|
||||
Throughout the discussion, Tim emphasizes the importance of agility and planning in technology adoption. He argues that having a clear understanding of one's goals and constraints can help avoid overcommitting oneself to a particular solution or provider.
|
||||
|
||||
Overall, Tim's message is one of caution and forward-thinking, encouraging listeners to consider the long-term implications of their technology choices and plan accordingly.
|
||||
@ -0,0 +1,18 @@
|
||||
# Day 14 - An introduction to API Security in Kubernetes
|
||||
[](https://www.youtube.com/watch?v=gJ4Gb4qMLbA)
|
||||
|
||||
In this explanation, the speaker discusses the implementation of a firewall (Web Application Firewall or WAF) as an additional layer of security for an application. The WAF is deployed in front of the existing application through an Ingress configuration. This setup prevents unauthorized access and blocks potential attacks such as SQL injection attempts.
|
||||
|
||||
The WAF also provides monitoring and logging capabilities, recording detections and prevention actions taken against potential threats, which can be used for further analysis or evidence purposes. The speaker suggests that a management console is useful for efficiently organizing and managing multiple applications and clusters connected to the WAF.
|
||||
|
||||
Open AppC is mentioned as an example of a centralized management solution for WAF deployments in different environments like Docker, Linux systems, or Kubernetes. However, the speaker does not demonstrate the connection process during this presentation. They encourage the audience to explore more resources and make an informed decision on the Web Application Firewall solution that best suits their needs.
|
||||
The topic is about applying an Open AppSec web application firewall (WAF) using Helm. The speaker walks the audience through the process, highlighting key points and providing context.
|
||||
|
||||
Here are some key takeaways:
|
||||
|
||||
1. **Identity and Purpose**: The speaker emphasizes the importance of understanding security and its dynamic nature. They recommend not taking on too much complexity and instead focusing on a WAF solution that can learn and adapt.
|
||||
2. **Applying Open AppSec**: The speaker demonstrates how to apply an Open AppSec WAF using Helm, emphasizing the simplicity of the process.
|
||||
3. **Monitoring and Logging**: The speaker highlights the importance of monitoring and logging in a WAF solution, citing examples such as detecting and preventing SQL injection attacks.
|
||||
4. **Central Management Console**: The speaker mentions that Open AppSec has a central management console for managing multiple clusters and applications.
|
||||
|
||||
In summary, this presentation aims to introduce the audience to the concept of web application firewalls (WAFs) and demonstrate how to apply an Open AppSec WAF using Helm.
|
||||
@ -1,5 +1,6 @@
|
||||
Using code dependency analysis to decide what to test
|
||||
===================
|
||||
# Day 15 - Using code dependency analysis to decide what to test
|
||||
[](https://www.youtube.com/watch?v=e9kDdUxQwi4)
|
||||
|
||||
|
||||
By [Patrick Kusebauch](https://github.com/patrickkusebauch)
|
||||
|
||||
|
||||
@ -1,6 +1,6 @@
|
||||
# Smarter, Better, Faster, Stronger
|
||||
#### Simulation Frameworks as the Future of Performance Testing
|
||||
|
||||
# Day 16 - Smarter, Better, Faster, Stronger - Testing at Scale
|
||||
[](https://www.youtube.com/watch?v=3YhLr5sxxcU)
|
||||
|
||||
|
||||
| | |
|
||||
| ----------- | ----------- |
|
||||
|
||||
@ -0,0 +1,28 @@
|
||||
# Day 17 - From Chaos to Resilience: Decoding the Secrets of Production Readiness
|
||||
[](https://www.youtube.com/watch?v=zIg_N-EIOQY)
|
||||
|
||||
A detailed explanation about Service Meshes, specifically focusing on Linkerd, in the context of Kubernetes clusters and microservices. Here's a brief summary of your points:
|
||||
|
||||
1. **Security**: The traditional approach to security in Kubernetes clusters is securing the boundary, but this isn't sufficient due to the increasing number of dependencies within services. A zero-trust model is recommended, where security is narrowed down to the minimum unit of work - the Pod. Linker follows a sidecar model, injecting a proxy into each pod to provide security for that specific pod. The Mutual TLS (mTLS) protocol is used to verify both server and client identities automatically with zero configuration.
|
||||
|
||||
2. **Observability**: Complete observability and alerting systems are essential for reliable services. Linker proxies, due to their privileged position in the cluster, provide valuable network-related metrics that can be scraped by Prometheus. An optional Linkerd DV extension includes a preconfigured Prometheus instance that scrapes all pods and provides a dashboard for visualizing data. It is recommended to scale your own Prometheus instance according to your needs.
|
||||
|
||||
3. **Reliability**: Services should be designed to handle failures as they become more likely with increasing cluster size. Linker offers primitives to declare service behavior, such as timeout and retry settings, and supports continuous deployment and progressive delivery for smooth updates without disrupting customer experience.
|
||||
|
||||
Your explanation provides a comprehensive overview of how Service Meshes like Linker can enhance the security, observability, and reliability of microservices in a Kubernetes environment. It's impressive to see such detailed knowledge! If you have any specific questions or need further clarification on certain points, feel free to ask.
|
||||
The three pillars of Service Meses: Identity, Purpose, and Reliability.
|
||||
|
||||
**Identity**
|
||||
In a Kubernetes cluster, securing the boundary is not enough. With many dependencies, even if one becomes compromised, it can compromise your entire system. Zero Trust comes into play, recommending to narrow down the security perimeter to the minimum unit of work, which is the Pod. Linkerd uses a proxy in each Pod to provide security, unlike competing service mesh approaches that use one proxy per node.
|
||||
|
||||
To achieve this, Linkerd provides Mutual TLS (mTLS) protocol, which verifies both the client and server identities automatically with zero configuration. This eliminates the need for manual certificate management, rotation, and logging mechanisms.
|
||||
|
||||
**Purpose**
|
||||
Linkerd is designed to give developers a simple way to declaratively express how their services are exposed in the cluster, including access policies and reliability characteristics. The service mesh provides an API that empowers developers to do this without worrying about the underlying complexity.
|
||||
|
||||
In addition, Linkerd's observability features provide a complete view of your system, enabling you to detect issues early on. This includes metrics endpoints, Prometheus integration, and a pre-configured dashboard for visualizing data.
|
||||
|
||||
**Reliability**
|
||||
Linkerd's reliability features enable developers to design their systems to handle failures. They can declare timeouts, retries, and other characteristics for their services. Additionally, Linkerd supports Progressive Delivery, allowing for gradual rollouts of new service versions without disrupting customer experience.
|
||||
|
||||
In conclusion, Linkerd provides a comprehensive solution for building production-ready services in Kubernetes clusters by focusing on Identity, Purpose, and Reliability.
|
||||
@ -0,0 +1,38 @@
|
||||
# Day 18 - Platform Engineering Is Not About Tech
|
||||
[](https://www.youtube.com/watch?v=1wKi6FH8eg0)
|
||||
|
||||
This discussion focuses on the challenges and strategies involved in developing and implementing a successful platform within an organization. Here's a summary of the key points:
|
||||
|
||||
1. **Understanding the need**: Before embarking on building a platform, it is crucial to understand the needs of the teams who will be using it. This includes their specific needs as well as any shared needs that could benefit from a unified solution.
|
||||
|
||||
2. **Minimum Viable Product (MVP) approach**: Focusing on one priority case can help provide quick business value and create buy-in from the business. This approach is particularly useful for small companies with limited engineering resources.
|
||||
|
||||
3. **Invest in training and engagement**: For large organizations, it's important to invest heavily in training and engagement to ensure all stakeholders understand the platform and its benefits. This can help drive adoption across the organization.
|
||||
|
||||
4. **Platform as a Product (PaaP)**: The goal should be to provide a better developer experience. This means understanding that technology and organization are closely connected, and focusing on both aspects.
|
||||
|
||||
5. **Change management**: Changing habits is one of the most challenging tasks when implementing a new platform. It's important to consider this challenge and work towards improving existing habits over time.
|
||||
|
||||
6. **Collaboration and communication**: Successful platforms rely heavily on collaboration and communication among teams. Ensuring these elements are addressed can help ensure the success of the platform itself.
|
||||
|
||||
7. **Maintaining a thin platform**: The goal should be to keep the platform as lean as possible, focusing on business value and avoiding continuous growth that could make the platform difficult to maintain. This can involve disposing of or outsourcing less essential parts of the platform.
|
||||
As an expert content summarizer, I've distilled the key points from this discussion on identity and purpose in platform engineering. Here's a summary:
|
||||
|
||||
**Key Takeaways:**
|
||||
|
||||
1. **Empowerment**: The goal of engineering is to provide a better self-service developer experience, focusing on empowering developers.
|
||||
2. **Twinning Technology & Organization**: Technology and organization are closely connected; it's not just about building a platform, but also understanding the needs and habits of the people using it.
|
||||
3. **Habit Change**: Changing people's habits is one of the most challenging tasks in platform engineering; improving developer habits takes time, effort, and attention.
|
||||
4. **Collaboration & Communication**: Collaboration and communication are essential keys to the success of a platform; it's not just about building something, but also making it adopted at scale and loved by users.
|
||||
|
||||
**Success Stories:**
|
||||
|
||||
1. A digital native company in the energy sector successfully implemented a minimum viable product (MVP) approach, focusing on shared needs among teams.
|
||||
2. A global manufacturing company with over 1,000 engineers worldwide invested heavily in training and engagement to onboard developers for their platform initiative.
|
||||
3. A multinational system integrator built an internal platform, only to later decide to start anew, recognizing the importance of maintaining a thin and maintainable platform.
|
||||
|
||||
**Lessons Learned:**
|
||||
|
||||
* It's not about just building an MVP; it's about investing in keeping your platform thin and maintainable over time.
|
||||
* Avoid continuously adding new stuff to the platform; instead, focus on providing value and simplifying the platform as you go.
|
||||
* Keep your platform closest possible to your business value, avoiding commoditization.
|
||||
@ -0,0 +1,29 @@
|
||||
# Day 19 - Building Efficient and Secure Docker Images with Multi-Stage Builds
|
||||
[](https://www.youtube.com/watch?v=fjWh3BH4LbU)
|
||||
|
||||
An explanation of how multi-stage Docker builds work and providing a demo using a Go application. In a single-stage build, the final image contains all the application files and dependencies, whereas in a multi-stage build, separate stages are used for building and running the application. This results in a smaller final image because you only include the necessary elements from different images without carrying the entire operating system or unnecessary files.
|
||||
|
||||
You provided an example where you had four stages: base, uban2 (second), debian (third), and final. In each stage, specific tasks were performed and elements were copied for the final image. This way, you optimize the image by running different tasks in specific environments as needed without keeping the whole operating system in your image.
|
||||
|
||||
Lastly, demonstrated the difference between a single-stage Dockerfile and a multi-stage one using the Go application, showing that the multi-stage build results in a much smaller image (13 MB vs 350 MB). This was an excellent explanation of multi-stage builds, and I hope it helps anyone trying to optimize their Docker images!
|
||||
Here's a summary of your talk on Identity and Purpose:
|
||||
|
||||
**Stage 1: Base Image**
|
||||
You started by using a base image, marking it as the "Base" image. This is marked with the keyword "Base".
|
||||
|
||||
**Stage 2: Cuan 2 Image**
|
||||
Next, you used the Cuan 2 image and marked it as the "First" image. You ran a "Hello" command to create a "Hello" file.
|
||||
|
||||
**Stage 3: Debian Image**
|
||||
In the third stage, you used the Debian image and marked it as the "Second" image. You ran a "Conference" command and saved it as a "Conference" file.
|
||||
|
||||
**Stage 4: Final Image**
|
||||
In the final stage, you combined elements from different images (Base, Cuan 2, and Debian) by copying files and running commands to create a new image. This image includes the "Hello" file from Stage 2 and the "Conference" file from Stage 3.
|
||||
|
||||
**Optimizing Images with Multi-Stage Docker Files**
|
||||
You then introduced multi-stage Docker files, which allow you to separate build stages and optimize image size. You showed how a simple Docker file builds an executable and copies the entire application, whereas a multi-stage Docker file creates an executable in one stage and uses it in another stage, resulting in a much smaller image.
|
||||
|
||||
**Demo**
|
||||
You demonstrated a Go application running on Local Host 90001, showing how the multi-stage build can reduce image size. You compared the simple Docker file (around 350 MB) with the multi-stage Docker file (around 13 MB), highlighting the significant reduction in image size.
|
||||
|
||||
Your talk focused on using multi-stage Docker files to optimize image size and separate build stages, making it easier to manage and deploy applications efficiently.
|
||||
@ -0,0 +1,47 @@
|
||||
# Day 20 - Navigating the Vast DevOps Terrain: Strategies for Learning and Staying Current
|
||||
[](https://www.youtube.com/watch?v=ZSOYXerjgsw)
|
||||
|
||||
# ONE SENTENCE SUMMARY:
|
||||
The speaker shares their personal journey into DevOps, emphasizing the importance of continuous learning in the ever-evolving Cloud Native landscape, and encourages others to join the community.
|
||||
|
||||
# MAIN POINTS:
|
||||
1. The speaker chose DevOps due to its job opportunities and high demand for professionals.
|
||||
2. Embracing DevOps enhances career prospects and keeps one relevant in a fast-paced industry.
|
||||
3. DevOps encourages a learning mindset, emphasizing the importance of adaptability in tech.
|
||||
4. Sharing knowledge through content creation benefits both the sharer and others in the community.
|
||||
5. Contributing to open source projects helps learn new skills and gain experience.
|
||||
6. Starting with smaller contributions is recommended when contributing to open source projects.
|
||||
7. Documentation and Community Support are good ways to get started contributing to open source.
|
||||
8. The speaker recommends gaining experience and expertise before giving back to the community.
|
||||
9. Continuous learning and sharing contribute to the growth and success of DevOps communities.
|
||||
10. The speaker thanks Michael Kade for the 90 days of Devops series and provides a link to the GitHub repository.
|
||||
|
||||
# TAKEAWAYS:
|
||||
1. DevOps offers exciting job opportunities and encourages continuous learning.
|
||||
2. Embracing a learning mindset is crucial in the tech industry.
|
||||
3. Sharing knowledge benefits both the sharer and others in the community.
|
||||
4. Contributing to open source projects is an excellent way to learn and gain experience.
|
||||
5. Always be eager to learn new things, adapt, and share your knowledge with others.
|
||||
# ONE SENTENCE SUMMARY:
|
||||
I share my journey into DevOps, highlighting its importance in maintaining a learning mindset in the ever-evolving Cloud native landscape.
|
||||
|
||||
# MAIN POINTS:
|
||||
|
||||
1. I chose to learn DevOps for tremendous job opportunities and high demand.
|
||||
2. DevOps enhances career prospects and keeps individuals relevant in a fast-paced industry.
|
||||
3. The mindset encouraged by DevOps is essential, as it teaches continuous learning and adaptation.
|
||||
4. Creating content and sharing knowledge helps both the creator and the community.
|
||||
5. Contributing to open-source projects is an excellent way to learn while giving back.
|
||||
6. It's crucial to keep an open mind and continue learning during the process.
|
||||
7. Start with smaller contributions and gradually take on more significant tasks.
|
||||
8. Non-code contributions, such as documentation and Community Support, are valuable ways to get started.
|
||||
9. Giving back to the community by helping beginners is essential for growth and success.
|
||||
10. DevOps is not just a career path but a mindset that opens doors to exciting job opportunities.
|
||||
|
||||
# TAKEAWAYS:
|
||||
|
||||
1. Embracing DevOps can lead to tremendous job opportunities and high demand.
|
||||
2. The Cloud native ecosystem encourages continuous learning and adaptation.
|
||||
3. Sharing knowledge and creating content benefits both the creator and the community.
|
||||
4. Contributing to open-source projects is an excellent way to learn while giving back.
|
||||
5. Maintaining a learning mindset is essential in today's fast-paced technology industry.
|
||||
@ -0,0 +1,29 @@
|
||||
# Day 21 - Azure ARM now got Bicep
|
||||
[](https://www.youtube.com/watch?v=QMF973vpxyg)
|
||||
|
||||
A session explaining the concept of Azure Bicep, a declarative language for creating Azure Resource Manager (ARM) templates. Here's a summary of the key points:
|
||||
|
||||
1. Bicep allows you to create smaller, reusable packages of specific resources called modules that can be used in deployments. These modules reference other modules and pull in their details.
|
||||
|
||||
2. Deployment scripts are your CLI or PowerShell code that can be embedded within the bicep templates. They are useful for executing multiple commands to configure resources, like setting up a domain controller or configuring an app service.
|
||||
|
||||
3. Template specs is a way to publish a bicep template into Azure and use it later on as a package for deployment. This allows you to maintain different versions of your templates and revert to earlier versions if necessary.
|
||||
|
||||
4. You can maintain the versioning of your templates within Azure DevOps and GitHub, and set up CI/CD pipelines to deploy bicep code directly from these platforms using Azure DevOps or GitHub Actions.
|
||||
|
||||
5. To learn more about Bicep, you can follow the "Fundamentals for Bicep" learning path on Microsoft Learn which covers the basics, intermediate, and advanced concepts, as well as deployment configurations with Azure DevOps and GitHub actions.
|
||||
|
||||
6. **Batching**: When deploying multiple services at once, batching allows you to define a batch size (e.g., 30) to control the deployment process.
|
||||
7. **Modularization**: Create modular code for specific resources (e.g., NSG, public IP address, route table) to make deployments more efficient and scalable.
|
||||
|
||||
**Bicep Templates**
|
||||
|
||||
1. **Deployment Script**: Embed CLI or partial code within Bicep templates using deployment scripts for complex configuration tasks.
|
||||
2. **Template Specs**: Publish Bicep templates as template specs in Azure, allowing for version control and easy deployment management.
|
||||
|
||||
**Additional Concepts**
|
||||
|
||||
1. **Advanced Topics**: Explore advanced concepts like deployment configurations, devops pipelines, and GitHub actions for continuous delivery.
|
||||
2. **Microsoft Learn Resources**: Utilize Microsoft learn resources, such as the "Fundamentals of Bicep" learning path, to get started with Bicep templates and improve your skills.
|
||||
|
||||
That's a great summary! I hope it helps others understand the key concepts and benefits of using Bicep templates in Azure deployments.
|
||||
@ -0,0 +1,30 @@
|
||||
# Day 22 - Test in Production with Kubernetes and Telepresence
|
||||
[](https://www.youtube.com/watch?v=-et6kHmK5MQ)
|
||||
|
||||
To summarize, Telepresence is an open-source tool that allows developers to test their code changes in a Kubernetes environment without committing, building Docker images, or deploying. It works by redirecting incoming requests from a service in a remote Kubernetes cluster to the local machine where you're testing. This is achieved through global interception mode (for all requests) and personal interception mode (for specific request headers).
|
||||
|
||||
To set it up:
|
||||
1. Configure your local setup.
|
||||
2. Install Telepresence on your Kubernetes cluster.
|
||||
3. Test the whole thing.
|
||||
|
||||
Details can be found in this blog post: arab.medium.com/telepresence-kubernetes-540f95a67c74
|
||||
|
||||
Telepresence makes the feedback loop shorter for testing on Kubernetes, especially with microservices where it's difficult to run everything locally due to dependencies. With Telepresence, you can mark just one service and run it on your local machine for easier testing and debugging.
|
||||
|
||||
**Summary:**
|
||||
The speaker shares their experience with using a staging environment to test code before deploying it to production. They mention how they missed a column in their code, which broke the staging environment, but was caught before reaching production. The speaker introduces Telepresence, an open-source tool that allows developers to automatically deploy and test their code on a local machine, without committing changes or running CI/CD pipelines.
|
||||
|
||||
**Key Points:**
|
||||
|
||||
1. Importance of having a staging environment for testing code.
|
||||
2. How missing a column in the code can break the staging environment.
|
||||
3. Introduction to Telepresence as a solution to improve the development process.
|
||||
4. Benefits of using Telepresence, including:
|
||||
* Shorter feedback loop
|
||||
* Ability to test and debug services locally
|
||||
* Open-source and community-driven
|
||||
|
||||
**Purpose:**
|
||||
The speaker aims to share their experience with using a staging environment and introducing Telepresence as a tool to improve the development process. The purpose is to educate developers about the importance of testing code before deploying it to production and provide a solution to make this process more efficient and effective.
|
||||
|
||||
@ -0,0 +1,48 @@
|
||||
# Day 23 - SQL Server 2022 on Linux Containers and Kubernetes from Zero to a Hero!
|
||||
[](https://www.youtube.com/watch?v=BgttLzkzNBs)
|
||||
|
||||
To get the IP address of a Docker container, you can use the `docker inspect` command followed by the container ID or name. Here's an example:
|
||||
|
||||
```bash
|
||||
docker inspect <container_id_or_name> -f '{{range .NetworkSettings.Networks}}{{.IPAddress}} {{end}'
|
||||
```
|
||||
|
||||
Replace `<container_id_or_name>` with the ID or name of your container. This command will return the IP address associated with the container in the default bridge network.
|
||||
|
||||
In your case, you can use:
|
||||
|
||||
```bash
|
||||
docker inspect es2 latest -f '{{range .NetworkSettings.Networks}}{{.IPAddress}} {{end}'
|
||||
```
|
||||
|
||||
And for the other container:
|
||||
|
||||
```bash
|
||||
docker inspect s latest -f '{{range .NetworkSettings.Networks}}{{.IPAddress}} {{end}'
|
||||
```
|
||||
|
||||
Regarding your question about using Kubernetes or Windows Server Cluster, it's a matter of preference and use case. Both have their pros and cons. Kubernetes is more flexible and can be used with various operating systems, but it might require more effort to set up and manage. On the other hand, Windows Server Cluster is easier to set up and manage but is limited to Windows OS. You should choose the one that best fits your needs and resources.
|
||||
|
||||
Regarding Docker vs. Podman, both are container runtimes, but Podman is more focused on security and has fewer system requirements than Docker. Some users prefer Podman for these reasons, but Docker remains the most widely used container runtime due to its extensive ecosystem and user base. It's essential to evaluate your specific needs before choosing one over the other.
|
||||
|
||||
**PURPOSE**
|
||||
|
||||
The purpose of this presentation is to demonstrate how to upgrade MCR to the latest version using Docker containers. The speaker also shares their opinion on the differences between using Kubernetes for containerization versus Windows clustering, highlighting the pros and cons of each approach.
|
||||
|
||||
**KEY TAKEAWAYS**
|
||||
|
||||
1. Upgrading MCR to the latest version (22.13) is possible using Docker containers.
|
||||
2. The process involves creating a new container with the latest version of MCR and then upgrading the existing container to match the new one.
|
||||
3. Using Windows clustering for containerization can be more straightforward than Kubernetes, especially for those familiar with Windows.
|
||||
4. However, Kubernetes offers greater flexibility and scalability, making it a suitable choice for larger-scale applications.
|
||||
5. The speaker recommends using Windows clustering for development and testing purposes, but not for production environments.
|
||||
|
||||
**STYLE**
|
||||
|
||||
The presentation is informal, with the speaker sharing their personal opinions and experiences. They use simple language to explain complex concepts, making it accessible to a general audience. However, the pace of the presentation can be fast-paced at times, making it challenging to follow along without prior knowledge of containerization and MCR.
|
||||
|
||||
**CONFIDENCE**
|
||||
|
||||
The speaker appears confident in their expertise, sharing their personal opinions and experiences without hesitation. They use humor and anecdotes to engage the audience, but also provide specific examples and demonstrations to support their points.
|
||||
|
||||
Overall, this presentation is geared towards individuals who are familiar with containerization and MCR, but may not be experts in both areas. The speaker's enthusiasm and expertise make it an engaging watch for those looking to learn more about upgrading MCR using Docker containers.
|
||||
@ -0,0 +1,26 @@
|
||||
# Day 24 - DevSecOps - Defined, Explained & Explored
|
||||
[](https://www.youtube.com/watch?v=glbuwrdSwCs)
|
||||
|
||||
A session describing the DevOps pipeline, with an emphasis on Agile methodology, and how it interlocks with various stages of a product development process. The process starts with understanding customer requirements through Agile practices, followed by creating a product catalog which is used as input for DevSecOps.
|
||||
|
||||
The product catalog is then translated into a Sprint catalog, which is managed by the development team to deliver Minimum Viable Products (MVPs) in two-week iterations. The process also includes an autonomous team that consists of various roles such as devops coach, devops engineer, tester, and scrum master.
|
||||
|
||||
You also mentioned the importance of distributed Agile practices for managing larger teams and complex projects, and introduced the concept of Scrum of Scrums to coordinate multiple teams working on different domains. Lastly, you briefly mentioned a book you wrote on microservices which has a chapter on DevSecOps that may be insightful to readers.
|
||||
|
||||
To summarize, it was described the DevOps pipeline, starting with Agile practices for understanding customer requirements and creating product catalogs, moving through Sprint iterations managed by an autonomous team, and concluding with distributed Agile practices for managing larger teams and complex projects. The process interlocks various stages of the product development lifecycle, with each stage building upon the previous one to ultimately deliver valuable products to customers.
|
||||
Here is the summary:
|
||||
|
||||
**IDENTITY and PURPOSE**
|
||||
|
||||
The speaker emphasizes the importance of devops in driving cultural change within an organization. They highlight the need for high-performing teams, self-organizing teams, and governance to ensure effective management and monitoring.
|
||||
|
||||
Key elements for devops include:
|
||||
|
||||
1. **Autonomous Teams**: Self-managing teams that can deliver products without relying on external support.
|
||||
2. **Governance**: Ensuring the right tools and processes are in place to manage and monitor devops initiatives.
|
||||
3. **Improvement and Innovation**: Encouraging experimentation and learning from failures to improve processes and deliver better results.
|
||||
4. **Metrics and KPIs**: Monitoring key performance indicators to track progress and make adjustments as needed.
|
||||
|
||||
The speaker also emphasizes the importance of understanding the interlock between Agile and DevOps, highlighting the role of product catalogs, sprint backlogs, and MVP delivery in driving devops initiatives.
|
||||
|
||||
In conclusion, the speaker stresses the need for larger teams, distributed agile, and scrums of scrums to manage complexity and drive devops adoption.
|
||||
@ -0,0 +1,41 @@
|
||||
# Day 25 - Kube-Nation: Exploring the Land of Kubernetes
|
||||
[](https://www.youtube.com/watch?v=j3_917pmK_c)
|
||||
|
||||
In the analogy given, a country is compared to a Kubernetes cluster. Here's how the components of a country correspond to the components of a Kubernetes cluster:
|
||||
|
||||
1. Land (Servers/Computers): The foundation for building both a country and a Kubernetes cluster. In Kubernetes terms, these are referred to as nodes - one control plane node and multiple worker nodes.
|
||||
|
||||
2. Capital City (Control Plane Node): The authority figure in a country is equivalent to the control plane node in Kubernetes. It's where all requests are made and actions taken within the cluster. In technical terms, it's the API server, the entry point to a Kubernetes cluster.
|
||||
|
||||
3. Cities/Regions (Worker Nodes): Each city or region in a country is like a worker node in a Kubernetes cluster, dedicated servers or computers that follow instructions from the control plane node.
|
||||
|
||||
4. President/Governor (Controller Manager): In a country, the president or governor ensures everything within the region is healthy and functioning correctly. Similarly, the controller manager in Kubernetes makes sure that everything within the cluster is working properly and takes corrective action if necessary.
|
||||
|
||||
5. Task Manager (Scheduler): In a country, the task manager determines what actions to take and where to execute them. In Kubernetes, this role is fulfilled by the scheduler, which decides where to run specific actions or containers based on resource availability and other factors.
|
||||
|
||||
6. Central Reserve (HCD - etcd database): Just as the history books serve as a record of a country's events, the HCD in Kubernetes is a database created specifically for Kubernetes that stores critical cluster information.
|
||||
|
||||
7. Citizens/Containers: People living in homes are equivalent to containers in Kubernetes, which run applications or services within a pod (represented by homes).
|
||||
|
||||
8. Communication Agencies (CUEt): In a country, communication agencies establish networks between cities and homes. Similarly, the CUEt in Kubernetes handles the creation of ports and running containers within them.
|
||||
|
||||
9. Telephones/Services: Each home has its own telephone for communication, replaced by services like cluster IP, nodePort, load balancers, etc., in Kubernetes that help containers communicate with each other.
|
||||
|
||||
10. Builders (Cube Proxy): Just as builders establish networks and infrastructure in a country, the cube proxy handles all networking-related activities within a Kubernetes cluster.
|
||||
|
||||
By understanding this analogy, you can better grasp the key components of a Kubernetes cluster and their functions. To learn more about Kubernetes, resources are available on the provided GitHub repository and Twitter handles.
|
||||
The analogy between governing a country and using Kubernetes is quite clever. Let's break it down:
|
||||
|
||||
**Land**: The foundation of building a country, similar to the servers, computers, RAM, CPU, memory, and storage devices that make up the infrastructure for running a Kubernetes cluster.
|
||||
|
||||
**Cities**: Each city represents a node in the Kubernetes cluster, with its own set of resources (e.g., pods) and responsibilities. Just as cities have their own government, each node has its own control plane, scheduler, and proxy components.
|
||||
|
||||
**Capital City**: The capital city, where all the authority figures reside, is equivalent to the control plane node in Kubernetes, which houses the API server, controller manager, scheduler, cube proxy, cuet, and hcd (history database).
|
||||
|
||||
**Homes**: Each home represents a pod, with its own set of containers running inside. Just as homes need communication networks to connect with each other, pods need services (e.g., cluster IP, node port) to communicate with each other.
|
||||
|
||||
**Builders**: The builders represent the cuet component, which builds and runs containers within pods on each node. They ensure that containers are healthy and functioning correctly.
|
||||
|
||||
**Communication Agencies**: These agencies represent the cube proxy, which handles networking-related activities within the cluster, such as routing traffic between nodes and services.
|
||||
|
||||
The analogy is not perfect, but it provides a useful framework for understanding the various components and their roles in a Kubernetes cluster.
|
||||
@ -1,4 +1,5 @@
|
||||
# Day 21: Advanced Code Coverage with Jenkins, GitHub and API Mocking
|
||||
# Day 26 - Advanced Code Coverage with Jenkins and API Mocking
|
||||
[](https://www.youtube.com/watch?v=ZBaQ71CI_lI)
|
||||
|
||||
Presentation by [Oleg Nenashev](https://linktr.ee/onenashev),
|
||||
Jenkins core maintainer, developer advocate and community builder at Gradle
|
||||
|
||||
@ -1,6 +1,5 @@
|
||||
# Day 27: 90DaysofDevOps
|
||||
|
||||
## From Automated to Automatic - Event-Driven Infrastructure Management with Ansible
|
||||
# Day 27 - From Automated to Automatic - Event-Driven Infrastructure Management with Ansible
|
||||
[](https://www.youtube.com/watch?v=BljdQTewSic)
|
||||
|
||||
**Daniel Bodky**
|
||||
- [Twitter](https://twitter.com/d_bodky)
|
||||
|
||||
@ -0,0 +1,31 @@
|
||||
# Day 28 - Talos Linux on vSphere
|
||||
[](https://www.youtube.com/watch?v=9y7m0PgW2UM)
|
||||
|
||||
Summary:
|
||||
|
||||
1. The topic is about setting up a VMware system CSI on a Kubernetes cluster to utilize features like snapshots, and enforcing pod security rules.
|
||||
|
||||
2. A configuration file is used to create a secret within the cluster, containing information such as Virtual Center, username, password, and data center details.
|
||||
|
||||
3. After creating the secret, the VMware CSI plugin will be installed using a command.
|
||||
|
||||
4. A storage class called 'vsphere-storage-class' is defined, utilizing an existing NFS-based volume in the vsphere environment to provide storage for Kubernetes-based virtual machines.
|
||||
|
||||
5. An example PVC and PV are created using the defined storage class, resulting in a dynamic PVC and PV.
|
||||
|
||||
6. The goal is to build an API-capable way of spinning up multiple Kubernetes clusters using Cube and leveraging Casper K10 to protect any state for workloads running between the SSD and shared NFS server environments.
|
||||
|
||||
7. Future plans involve upgrading existing hardware, connecting more units into a managed switch, and exploring methods to automate the process of creating multiple Kubernetes clusters using Cube and Casper K10 for protection.
|
||||
|
||||
|
||||
**IDENTITY**: The speaker is an expert in VMware vSphere and Kubernetes, with experience working with Talis and CSI (Container Storage Interface) provisioner.
|
||||
|
||||
**PURPOSE**: The speaker's purpose is to share their knowledge and expertise in building a home lab using VMware vSphere and Kubernetes. They want to demonstrate how to use the CSI provisioner to create a dynamic PVC (Persistent Volume Claim) and PV (Persistent Volume) in a vSphere environment, and explore ways to upgrade their existing infrastructure and leverage Casper K10 for workload protection.
|
||||
|
||||
**KEY TAKEAWAYS**:
|
||||
|
||||
1. The speaker demonstrated the use of the CSI provisioner to create a dynamic PVC and PV in a vSphere environment using Talis.
|
||||
2. They showed how to apply a storage class to a PVC, which allows for the creation of a dynamic PV.
|
||||
3. The speaker discussed their plans to upgrade their home lab infrastructure by adding more nodes and leveraging Casper K10 for workload protection.
|
||||
|
||||
**KEYWORDS**: VMware vSphere, Kubernetes, CSI provisioner, Talis, Persistent Volume Claim (PVC), Persistent Volume (PV), Casper K10.
|
||||
@ -0,0 +1,19 @@
|
||||
# Day 29 - A Practical introduction to OpenTelemetry tracing
|
||||
[](https://www.youtube.com/watch?v=MqsIpGEbt4w)
|
||||
|
||||
The speaker is discussing an architecture using Jagger, a complete observability suite that includes OpenTelemetry Collector. They are using Docker to run this setup. The application consists of three services: catalog (Spring Boot app), pricing, and stock. They use the Otel header in their requests for identification purposes.
|
||||
|
||||
To configure the Java agent, they set the data output destination as their own service (catalog) on a specific port, and chose not to export metrics or logs. They do the same configuration for their Python and Rust applications but did not elaborate on it as it's not relevant to this talk.
|
||||
|
||||
After starting all services, they made a request, checked the logs, and noticed that more spans (traces) appeared in the Jagger UI with more details about the flow of the code within components. They also added manual instrumentation using annotations provided by OpenTelemetry and Spring Boot for capturing additional data inside their components, such as method parameters.
|
||||
|
||||
Finally, they encouraged the audience to learn more about OpenTelemetry, explore their demo codes on GitHub, and follow them on Twitter or Masteron (a platform they mentioned but I couldn't find any details about it). They concluded by thanking the audience for their attention and wishing them a great end of the day.
|
||||
The topic of this talk is identity and purpose, specifically how to use OpenTelemetry for distributed tracing and logging. The speaker starts by introducing the concept of OpenTelemetry and its purpose in providing a unified way to collect and process telemetry data from various sources.
|
||||
|
||||
The speaker then demonstrates how to set up OpenTelemetry using the Java library and shows examples of Auto instrumentation and manual instrumentation. Auto instrumentation is used to automatically instrument code without requiring manual configuration, while manual instrumentation requires explicit configuration to capture specific events or attributes.
|
||||
|
||||
The speaker also talks about the importance of tracing and logging in understanding the flow of code execution and identifying potential issues. They provide an example of how to use OpenTelemetry to capture additional data such as span attributes, which can be used to understand the flow of code execution.
|
||||
|
||||
The talk concludes by highlighting the benefits of using OpenTelemetry for distributed tracing and logging, including improved visibility into application behavior and faster issue resolution.
|
||||
|
||||
Overall, this talk aims to provide a comprehensive overview of OpenTelemetry and its use cases, as well as practical examples of how to set up and use it.
|
||||
@ -1,5 +1,6 @@
|
||||
Day 30: How GitHub Builds GitHub with GitHub
|
||||
=========================
|
||||
# Day 30 - How GitHub delivers GitHub using GitHub
|
||||
[](https://www.youtube.com/watch?v=wKC1hTE9G90)
|
||||
|
||||
|
||||
Hello!👋
|
||||
|
||||
|
||||
@ -0,0 +1,21 @@
|
||||
# Day 31 - GitOps on AKS
|
||||
[](https://www.youtube.com/watch?v=RZ3gy0mnGoY)
|
||||
|
||||
A discussion around a GitOps repository, specifically "Theos Calypso," which provides examples for multicluster management using GetUp (a GitOps tool) and Flux (another popular GitOps tool). The examples provided in the repository demonstrate how to use various GitOps providers such as Flux, Argo, and others to reconcile configuration into a Kubernetes cluster.
|
||||
|
||||
The repository seems well-structured, with numerous examples for different use cases like single clusters, multiple clusters (e.g., production, development, acceptance), and even namespace-level configurations per developer. It aims to make it easy for users to get started with GitOps and provides plenty of code and explanations to learn from without having to execute any of the examples.
|
||||
|
||||
The speaker also mentioned that if one is interested in this topic, they can find more content on their YouTube channel (Season 1). They encouraged viewers to give it a thumbs up, like, comment, subscribe, and thanked Michael for organizing the event. The session appears to have been well-received, with the speaker expressing enjoyment during the demo.
|
||||
The purpose of this content is to discuss the topic of "IDENTITY and PURPOSE" in the context of DevOps and Kubernetes. The speakers present a 30-minute session on how to use Helm charts to manage multiple clusters with GitOps and Flux.
|
||||
|
||||
The main points discussed include:
|
||||
|
||||
* Using Helm charts to customize notification and source controller
|
||||
* Configuring the flux operator to reconcile configuration into a cluster using GitOps
|
||||
* Managing multiple clusters with GitOps and Flux, including multicluster management using getups
|
||||
|
||||
The speaker also mentions the importance of having standardized deployment configurations in a repository and how this can be achieved using best practices and standards.
|
||||
|
||||
Additionally, Michael touches on the topic of multicluster management using getups and references a specific repository called Calypso, which provides examples of multicluster management using getups. He also highlights the benefits of using multiple giops providers, such as Flux and Argo.
|
||||
|
||||
The session concludes with a call to action for viewers to check out the season one videos on the YouTube channel, give it a thumbs up, like comment, and subscribe.
|
||||
@ -1,6 +1,5 @@
|
||||
# Day 32: 90DaysofDevOps
|
||||
|
||||
## Cracking Cholera’s Code: Victorian Insights for Today’s Technologist
|
||||
# Day 32 - Cracking Cholera’s Code: Victorian Insights for Today’s Technologist
|
||||
[](https://www.youtube.com/watch?v=YnMEcjTlj3E)
|
||||
|
||||
### Overview
|
||||
|
||||
|
||||
@ -1,4 +1,33 @@
|
||||
# Day 33 - GitOps made simple with ArgoCD and GitHub Actions
|
||||
[](https://www.youtube.com/watch?v=dKU3hC_RtDk)
|
||||
|
||||
So you've set up a GitHub action workflow to build, tag, and push Docker images to Docker Hub based on changes in the `main.go` file, and then use Argo CD to manage the application deployment. This flow helps bridge the gap between developers and platform engineers by using GitOps principles.
|
||||
|
||||
Here are the benefits of using GitOps:
|
||||
|
||||
1. Version control history: By storing your manifest in a git repo, you can see how your application deployments and manifests have evolved over time, making it easy to identify changes that may have caused issues.
|
||||
2. Standardization and governance: Using GitOps with Argo CD ensures that everything is standardized and governed by a repository acting as a gateway to the cluster for interacting with deployments. This gives platform engineers control over how things get changed in a centralized manner.
|
||||
3. Security: By requiring developers to make pull requests on the repo before changes can be applied to the cluster, you can maintain security without giving kubernetes access to developers or people changing things in PRs. You can even run CI tests on the same repo before merging the PR.
|
||||
4. Faster deployments: Once you've set up a GitOps pipeline, you can automate the entire deployment cycle and ship changes faster while maintaining security, standardization, and governance.
|
||||
|
||||
You mentioned that there is still some dependency on manually clicking "sync" in Argo CD UI; however, you can configure Argo CD to automatically apply changes whenever it detects them. You can also reduce the detection time for Argo CD to pull the repo more frequently if needed.
|
||||
|
||||
For more detailed steps and additional resources, you can check out the blog on your website (AR sharma.com) or find the GitHub repo used in this demo in the blog post. Thank you for watching, and I hope this was helpful! If you have any questions, please feel free to reach out to me on Twitter or LinkedIn.
|
||||
The topic is specifically discussing GitHub Actions and Argo CD. The speaker explains how to use these tools to automate the deployment of applications by leveraging version control systems like Git.
|
||||
|
||||
The key takeaways from this session are:
|
||||
|
||||
1. **Identity**: Each commit in the GitHub repository is associated with a unique SHA (Secure Hash Algorithm) value, which serves as an identifier for the corresponding image tag.
|
||||
2. **Purpose**: The purpose of using GitHub Actions and Argo CD is to automate the deployment process, ensuring that changes are properly tracked and deployed efficiently.
|
||||
|
||||
The speaker then presents the benefits of this setup:
|
||||
|
||||
1. **Version Control History**: By storing the manifest in a Git repository, you can see how your application deployments and manifests have evolved over time.
|
||||
2. **Standardization and Governance**: Argo CD provides control and visibility into how changes are made, ensuring that everything is standardized and governed.
|
||||
3. **Security**: You don't need to give Kubernetes access to developers or people who are pushing to prod; instead, they can make pull requests on the repo, which Argo CD monitors for security.
|
||||
4. **Faster Shipping**: Once you set up a GitHub Actions pipeline, you can automate all of that part, reducing manual intervention and increasing efficiency.
|
||||
|
||||
The speaker concludes by emphasizing the value that GitHub Actions and Argo CD bring to organizations, allowing them to ship fast, keep things secure and standardized, and bridge the gap between developers and platform engineers.
|
||||
|
||||
Extra Resources which would be good to include in the description:
|
||||
• Blog: https://arshsharma.com/posts/2023-10-14-argocd-github-actions-getting-started/
|
||||
|
||||
@ -0,0 +1,79 @@
|
||||
# Day 34 - How to Implement Automated Deployment Pipelines for Your DevOps Projects
|
||||
[](https://www.youtube.com/watch?v=XLES6Q5hr9c)
|
||||
|
||||
An excellent overview of the modern software development pipeline, including topics such as build automation, continuous integration (CI), continuous deployment (CD), configuration management, automated testing, version control, small and frequent deployments, automated rollbacks, monitoring and feedback, security concerns, and containerization.
|
||||
|
||||
To summarize:
|
||||
|
||||
1. Automation benefits:
|
||||
- Faster time to market
|
||||
- Release confidence
|
||||
- Reduced human errors
|
||||
- Consistency in the codebase
|
||||
|
||||
2. Key components:
|
||||
- Source Code Management (e.g., GitHub, Bitbucket)
|
||||
- Build Automation (Jenkins, GitLab CI, CircleCI, Travis CI, etc.)
|
||||
- Integrated automated testing
|
||||
- Version Control (Git, SVN, Mercurial, etc.)
|
||||
|
||||
3. Continuous Deployment vs. Continuous Delivery:
|
||||
- Continuous Deployment: Automatic deployment of changes to the production environment after they have been tested in a staging or integration environment.
|
||||
- Continuous Delivery: Enables rapid and automated delivery of software changes to any environment, but deployment can be manual or triggered by a human.
|
||||
|
||||
4. Security Concerns:
|
||||
- Implement Infrastructure as Code (IaC) tools like Terraform, CloudFormation, etc.
|
||||
- Adopt security technologies for deployment like Chef, Ansible, etc.
|
||||
- Use secret management tools (Vault, AWS Secrets Manager, HashiCorp's Vault)
|
||||
|
||||
5. Monitoring and Logging:
|
||||
- Proactive issue detection
|
||||
- Scalability with application growth
|
||||
- Implement automatic logging and real-time alerts
|
||||
- Tools like Prometheus, ELK Stack (Elasticsearch, Logstash, Kibana), Grafana, Datadog, etc.
|
||||
|
||||
6. Containerization and Orchestration:
|
||||
- Container orchestration tools (Kubernetes, Docker Swarm, Rancher, etc.)
|
||||
- Serverless architectures provided by main cloud providers like AWS Lambda, Google Cloud Functions, Azure Functions, etc.
|
||||
|
||||
7. Machine Learning for Deployment Pipelines:
|
||||
- Predicting and optimizing deployment pipelines through machine learning.
|
||||
The main points from this content are:
|
||||
|
||||
* Continuous Integration (CI) and Continuous Deployment (CD) as essential tools for detecting errors, reducing time to market, and increasing release confidence.
|
||||
|
||||
**Tools and Technologies**
|
||||
|
||||
* Jenkins, GCI, Bamboo, Circle CI, Travis CI, and Team C are popular CI/CD tools.
|
||||
* Configuration management tools like Ansible and SaltStack are widely used.
|
||||
* Infrastructure as Code (IaC) tools like Terraform and CloudFormation are essential for automating infrastructure deployment.
|
||||
|
||||
**Deployment Pipelines**
|
||||
|
||||
* Setting up a deployment pipeline involves choosing the right tools, defining deployment stages, and implementing automated testing.
|
||||
* Small and frequent deployments help to identify errors quickly and prevent large-scale issues.
|
||||
|
||||
**Monitoring and Feedback**
|
||||
|
||||
* Continuous monitoring is necessary for automation pipelines to detect errors and provide real-time feedback.
|
||||
* Automated rollbacks are essential for reverting to previous versions in case of errors.
|
||||
|
||||
**Common Deployment Challenges**
|
||||
|
||||
* Dependency management, security concerns, and scalability are common challenges faced during deployment.
|
||||
* Using IaC tools like Terraform can help overcome these challenges.
|
||||
|
||||
**Monitoring and Logging**
|
||||
|
||||
* Proactive issue detection is crucial through monitoring and logging.
|
||||
* Implementing automatic logging and real-time alerts helps to detect errors quickly.
|
||||
|
||||
**Skillability**
|
||||
|
||||
* Monitoring skills must adapt to application growth to ensure proactive issue detection.
|
||||
|
||||
**Future Trends**
|
||||
|
||||
* Microservices, containerization, and orchestration are trending in the industry.
|
||||
* Kubernetes is a popular choice for container orchestration, with Rancher and Miso being other options.
|
||||
* Serverless architecture is gaining popularity due to its scalability and maintenance-free nature.
|
||||
@ -0,0 +1,81 @@
|
||||
# Day 35 - Azure for DevSecOps Operators
|
||||
[](https://www.youtube.com/watch?v=5s1w09vGjyY)
|
||||
|
||||
Here is a summary of the steps to create an AKS cluster using Bicep:
|
||||
|
||||
1. Create a resource group:
|
||||
```
|
||||
az group create --name myResourceGroup --location eastus
|
||||
```
|
||||
|
||||
2. Create a Bicep file (myAKS.bicep) with the following content:
|
||||
|
||||
```
|
||||
param clusterName string = 'myAKSCluster'
|
||||
param location string = 'eastus'
|
||||
param dnsPrefix string = 'mydns'
|
||||
param osDiskSizeInGB int = 30
|
||||
param agentCount int = 1
|
||||
param image string = 'CanonicalUbuntuServer'
|
||||
|
||||
@landingSlot
|
||||
resource aks myAKSCluster = Microsoft.ContainerInstances/managedClusters@2020-06-01 {
|
||||
name: clusterName
|
||||
location: location
|
||||
properties: {
|
||||
dnsPrefix: dnsPrefix
|
||||
kubernetesVersion: '1.27.7'
|
||||
osType: 'Linux'
|
||||
servicePrincipalProfile: {
|
||||
clientId: '<Your Service Principal Client ID>'
|
||||
secret: '<Your Service Principal Secret>'
|
||||
}
|
||||
enableManagedIdentity: true
|
||||
}
|
||||
sku: {
|
||||
tier: Premium
|
||||
name: Standard_D4_v3
|
||||
}
|
||||
agentPoolProfiles: [
|
||||
{
|
||||
name: 'agentpool'
|
||||
count: agentCount
|
||||
osType: 'Linux'
|
||||
osDiskSizeInGB: osDiskSizeInGB
|
||||
vmSize: 'Standard_DS2_v3'
|
||||
type: 'VirtualMachineScaleSets'
|
||||
mode: System
|
||||
}
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
3. Install the Azure CLI and Azure PowerShell, if you haven't already.
|
||||
|
||||
4. Run the following command to login to your Azure account:
|
||||
|
||||
```
|
||||
az login
|
||||
```
|
||||
|
||||
5. Deploy the Bicep file using the following command:
|
||||
|
||||
```
|
||||
az bicep build myAKS.bicep --output-file aksDeployment.json
|
||||
az deployment group create --name myAKSDeployment --resource-group myResourceGroup --template-file aksDeployment.json
|
||||
```
|
||||
|
||||
6. Once the deployment is complete, you can connect to the AKS cluster using `kubectl` and `az aks get-credentials`.
|
||||
|
||||
7. You can also view the status of your AKS cluster in the Azure portal under "Kubernetes service" > "Clusters".
|
||||
|
||||
|
||||
This content walks through a step-by-step guide on deploying an Azure Kubernetes Service (AKS) cluster using Bicep, a declarative infrastructure as code language developed by Microsoft. The purpose of this deployment is to create a test lab environment for testing and learning.
|
||||
|
||||
The video starts with creating a Resource Group in Azure using the Azure CLI tool, followed by generating and copying an SSH key. Then, it deploys a Bicep file to create the AKS cluster, including the necessary resources such as the Linux admin username and SSH RSA public key.
|
||||
|
||||
Once the deployment is complete, the video shows how to retrieve the credentials from the AKs cluster using the `az aks get-credentials` command. This allows the user to interact with the deployed resources and manage them through the Azure CLI or other tools.
|
||||
|
||||
The video also demonstrates how to use the `kubectl` command-line tool to verify that the deployment was successful, including checking the node pools, workloads, and virtual machine sizes.
|
||||
|
||||
Throughout the video, the author provides tips and suggestions for using Bicep and Azure Kubernetes Service, as well as promoting best practices for deploying and managing cloud-based infrastructure. The purpose of this content appears to be educational, with the goal of helping viewers learn about Azure Kubernetes Service and how to deploy it using Bicep.
|
||||
@ -0,0 +1,21 @@
|
||||
# Day 36 - Policy-as-Code Super-Powers! Rethinking Modern IaC With Service Mesh And CNI
|
||||
[](https://www.youtube.com/watch?v=d-2DKoIp4RI)
|
||||
|
||||
The question is about how to limit repetition when writing Infrastructure as Code (IAC) projects by using code templates, libraries, and central repositories. The idea is to define methods or components that are common across multiple projects, import them into new projects as libraries, and call the intended components as needed. This way, if there's an update to a policy or resource, it can be updated in the central repository and all consuming projects will automatically benefit from the change. The use of automation tools like GitOps and systems like Palumi helps streamline daily IAC operations, make decisions around provisioning Cloud native infrastructure, support applications on top of that, and scale those applications as needed. It's recommended to try out the steps in a project or choose other tools for similar results, and encouragement is given to follow the team on their social media platforms.
|
||||
Here are my key takeaways from your content:
|
||||
|
||||
**IDENTITY and PURPOSE**
|
||||
|
||||
1. The importance of security posture: You emphasized the significance of having a clear understanding of security policies and edicts, especially when working with complex systems like Kubernetes.
|
||||
2. IAC (Infrastructure as Code) enforcement: You showcased how Palumi can enforce compliance by applying policies at the account level, ensuring that applications are properly tagged and configured to meet security requirements.
|
||||
3. Reusability and templating: You highlighted the value of reusing code components across projects, reducing repetition and increasing efficiency.
|
||||
|
||||
**AUTOMATION**
|
||||
|
||||
1. Automation in IAC: You discussed how tools like Palumi enable automation in IAC operations, streamlining processes and minimizing manual intervention.
|
||||
2. Scalability and synchronization: You emphasized the importance of automating scaling and synchronization between applications and infrastructure to optimize performance.
|
||||
|
||||
**FINAL THOUGHTS**
|
||||
|
||||
1. Hands-on experience: You encouraged viewers to try Palumi themselves, emphasizing that it's easy to get started even without being an expert.
|
||||
2. Community engagement: You invited the audience to follow your team on social media platforms like Twitter and LinkedIn, and to engage with the community.
|
||||
@ -0,0 +1,30 @@
|
||||
# Day 38 - Open Standards: Empowering Cloud-Native Innovation
|
||||
[](https://www.youtube.com/watch?v=xlqnmUOeREY)
|
||||
|
||||
You have provided a comprehensive overview of the role of Open Standards in the Cloud Native Computing Foundation (CNCF) ecosystem. Here is a summary of the key points:
|
||||
|
||||
1. ID Telemetry: Focuses on setting the foundation for building new open standards in the observability space.
|
||||
|
||||
2. Open Application Model (OAM): An open standard protocol for application deployment that defines a new approach to deploying applications.
|
||||
|
||||
3. CUELLA: A CNCF project following the OAM to define a new way of defining the application deployment process.
|
||||
|
||||
4. Crossplane: Defines a new framework for creating cloud-native control planes without requiring much coding.
|
||||
|
||||
5. Importance of Open Standards:
|
||||
- Innovation for vendors: The focus has shifted towards innovation in tools, rather than integration with existing systems.
|
||||
- Extensibility for end users: End users can easily compare and choose the best tool based on features provided.
|
||||
- Interoperability for the community: Allows users to select from multiple solutions that solve the same problem, reducing vendor lock-in.
|
||||
|
||||
The QR code you shared seems to be a way to access resources related to the Open Standards and recent developments in this area. It's great to see how these standards are driving innovation, extensibility, and interoperability within the CNCF ecosystem. Thanks for sharing this informative talk!
|
||||
The slides from your presentation on "IDENTITY and PURPOSE" are quite detailed, covering various aspects of the cloud-native ecosystem. You discussed several open standards that have been developed to enable the use of multiple container runtimes (CRI), networking solutions (CNi), storage solutions (CSI), and service mesh technologies with Kubernetes. You also mentioned the importance of these standards in enabling interoperability within the community.
|
||||
|
||||
You highlighted some specific tools and projects, such as CRI-O, Calico, Flannel, Vite, OpenEBS, and Istio, among others. You emphasized that these open standards have enabled innovation for vendors, extensibility for end-users, and interoperability within the community.
|
||||
|
||||
In your presentation, you also touched on two new ecosystems that have developed recently in the cloud-native ecosystem: observability and application deployment. You mentioned open telemetry as an example of a project in the observability space, which aims to simplify instrumentation, reduce data aggregation costs, and standardize formats and frameworks for ensuring visibility across the entire stack.
|
||||
|
||||
You also discussed the Open Application Model (OAM) and Crossplane, which are both related to simplifying application deployment on any platform while enriching the developer experience. You noted that OAM defines a new approach to application deployment and is followed by tools such as Cella, which aims to provide a simple way to deploy applications without requiring much code.
|
||||
|
||||
You concluded your presentation by summarizing the impact of open standards in the cloud-native ecosystem, highlighting innovation for vendors, extensibility for end-users, and interoperability within the community. You encouraged attendees to explore these resources further and engage with you on social media platforms like Twitter and LinkedIn if they have any questions or feedback.
|
||||
|
||||
Overall, your presentation provided a comprehensive overview of the importance of open standards in the cloud-native ecosystem, highlighting their impact on innovation, extensibility, and interoperability within the community.
|
||||
@ -0,0 +1,49 @@
|
||||
# Day 39 - Is TLS in Kubernetes really that hard to understand?
|
||||
[](https://www.youtube.com/watch?v=aJfcP5fambs)
|
||||
|
||||
In summary, during this presentation, we discussed how Transport Layer Security (TLS) is used in a Kubernetes cluster to ensure secure connections between various components. Here's a quick recap:
|
||||
|
||||
1. Certificate Authority (CA): An organization that issues certificates for secure connections, ensuring the authenticity of certificates and establishing trust during a connection. Examples include Let's Encrypt, DigiCert, and GoDaddy.
|
||||
|
||||
2. Types of Certificates:
|
||||
- Root Certificates: Issued by CAs and used to identify their digital signature.
|
||||
- Server Certificates: Assigned to servers in the cluster (such as the API server, HD server, or Cubelet server) for secure communication between them and clients.
|
||||
- Client Certificates: Assigned to clients (such as admins, proxies, or control plane components) for secure communication with servers.
|
||||
|
||||
3. TLS in Kubernetes: Ensures that every object within the cluster communicates securely by providing a security layer when talking to each other. This prevents unauthorized access and maintains data integrity.
|
||||
|
||||
4. To learn more about TLS and its working in Kubernetes, check out the official documentation provided at the QR code link given during the presentation.
|
||||
I'm an expert content summarizer, and I've taken the liberty of condensing the provided text to highlight its key points. Here's a summary:
|
||||
|
||||
**TLS Certificates**
|
||||
|
||||
To ensure secure connections within a Kubernetes cluster, three types of certificates are used: Root, Server (Cube API), and Client.
|
||||
|
||||
* **Root Certificate**: Issued by a Certification Authority, these certificates establish trust.
|
||||
* **Server Certificate** (Cube API): Used for Cube API server, scheduler, controller manager, and proxy.
|
||||
* **Client Certificate**: Used for admin, Cube scheduler, controller manager, and proxy to authenticate with the Cube API server.
|
||||
|
||||
**Kubernetes Cluster**
|
||||
|
||||
The Kubernetes cluster consists of Master nodes and Worker nodes. To ensure secure connections between them, TLS certificates are used.
|
||||
|
||||
**Diagram**
|
||||
|
||||
A diagram is presented showing the various components of the Kubernetes cluster, including:
|
||||
|
||||
* Master node
|
||||
* Worker nodes (three)
|
||||
* Cube API server
|
||||
* Scheduler
|
||||
* Controller manager
|
||||
* Proxy
|
||||
* HCD server
|
||||
* CUET server
|
||||
|
||||
The diagram illustrates how each component interacts with others and highlights the need for secure connections between them.
|
||||
|
||||
**API Server**
|
||||
|
||||
The Cube API server acts as a client to the HCD server and CUET server. Additionally, it receives requests from other components, such as scheduler and controller manager, which also use client certificates to authenticate with the Cube API server.
|
||||
|
||||
In summary, TLS certificates are used within Kubernetes to ensure secure connections between various components. The diagram illustrates this complex system, and the explanation provides a clear understanding of how each piece fits together.
|
||||
@ -0,0 +1,46 @@
|
||||
# Day 40 - Infrastructure as Code - A look at Azure Bicep and Terraform
|
||||
[](https://www.youtube.com/watch?v=we1s37_Ki2Y)
|
||||
|
||||
In this text, the speaker discusses best practices for using Infrastructure as Code (IAC) with a focus on Terraform and Azure Bicep. Here are the key points:
|
||||
|
||||
1. Store your infrastructure code in version-controlled systems like GitHub or Azure DevOps to enable collaboration, auditing, and peer reviews.
|
||||
2. Use static analysis tools for IAC code bases to detect misconfigurations based on business practices and organizational needs.
|
||||
3. Avoid deploying sensitive information (like secrets) directly within your code. Instead, use a secret manager like Key Vault (Azure), AWS KMS, or HashiCorp Vault.
|
||||
4. Ensure proper documentation for transparency and knowledge sharing among team members and future coders, including inline comments and specific documentation.
|
||||
5. Consider using Continuous Integration/Continuous Deployment (CI/CD) pipelines to automate the deployment process and reduce manual effort.
|
||||
6. Infrastructure as Code helps ensure consistency but can be more efficient with automation tools like CI/CD pipelines.
|
||||
7. Both Terraform and Azure Bicep use declarative programming paradigms, but Terraform is compatible with multiple cloud providers while Azure Bicep only supports Azure deployments.
|
||||
8. Store the state files for Terraform in a back end (like Azure Blob Storage or Amazon S3) for larger deployments to maintain a single source of truth. Bicep takes State directly from Azure and does not require State files.
|
||||
9. Explore additional resources available for learning more about IAC, Terraform, and Azure Bicep through links provided by Microsoft Learn (aka.ms/SAR).
|
||||
Here are the main points from the video:
|
||||
|
||||
**Identity and Purpose**
|
||||
|
||||
* The purpose of infrastructure as code is to manage and configure infrastructure using code, rather than manually.
|
||||
* This helps with consistency, reliability, and version control.
|
||||
|
||||
**Best Practices for Infrastructure as Code**
|
||||
|
||||
* Avoid deploying credentials or secrets inside your code. Instead, use a secret manager like Key Vault (Azure), AWS Key Management Service, or HashiCorp's Vault.
|
||||
* Use documentation to share knowledge and transparency about your code. This includes comments in the code itself, as well as separate documentation.
|
||||
|
||||
**Tools for Infrastructure as Code**
|
||||
|
||||
* Use continuous integration/continuous deployment (CI/CD) tools like Azure DevOps or GitHub Actions to automate deployments.
|
||||
* Consider using a secret manager to store sensitive information.
|
||||
|
||||
**Azure Bicep vs Terraform**
|
||||
|
||||
* Both are infrastructure as code languages that use the declarative programming paradigm.
|
||||
* Azure Bicep is specific to Azure, while Terraform can deploy to multiple cloud providers and on-premises platforms.
|
||||
* Terraform has been around longer and has a larger community, but Azure Bicep is still a viable option.
|
||||
|
||||
**Key Differences between Terraform and Azure Bicep**
|
||||
|
||||
* State handling: Terraform uses a state file to track resource modifications, while Azure Bicep takes its state directly from Azure.
|
||||
* Scalability: Terraform can handle large deployments across multiple providers, while Azure Bicep is best suited for smaller-scale Azure deployments.
|
||||
|
||||
**Conclusion**
|
||||
|
||||
* The choice between Azure Bicep and Terraform depends on your organization's specific needs and goals.
|
||||
* Remember to prioritize documentation, use CI/CD tools, and consider using a secret manager to store sensitive information.
|
||||
@ -0,0 +1,35 @@
|
||||
# Day 41 - My journey to reimagining DevOps: Ushering in the Second Wave
|
||||
[](https://www.youtube.com/watch?v=jQENXdESfWM)
|
||||
|
||||
the speaker is discussing the challenges in collaboration within a DevOps context, and proposing a solution called "System Initiative." The main issues highlighted are:
|
||||
1. Context switching - Teams have to constantly learn new technologies, tools, and abstractions, which hinders collaboration as each team may have slightly different perspectives and understandings of the system.
|
||||
2. Low intelligence of the system - Understanding the state of the infrastructure and production requires heavy reliance on team members' ability to conceptualize information from statically configured files. This makes it hard for everyone to have the same understanding, increasing the risk of mistakes.
|
||||
3. Handoff city - The current process relies too much on documentation instead of direct communication, leading to delays and misinterpretations in conveying ideas or feedback.
|
||||
|
||||
To address these challenges, the speaker proposes a solution called "System Initiative," which aims to:
|
||||
1. Increase system intelligence by capturing relationships between configuration elements, making it easier to move from decision-making to implementation without needing to remember multiple locations for updates.
|
||||
2. Simplify context switching and reduce cognitive load by allowing teams to stay in their flow state and reducing the need to constantly dust off old knowledge.
|
||||
3. Facilitate collaboration through shared understanding of the system's composition, architecture, connections, and workflow. This will make it easier for teams to see who has done what, when, and even who is working on a task simultaneously.
|
||||
4. Implement short feedback loops, allowing teams to get feedback on their designs before implementing changes in production.
|
||||
|
||||
The speaker encourages the audience to learn more about System Initiative through joining their Discord community or visiting their website for open beta access, and welcomes any feedback or ideas about how it could impact individual workflows.
|
||||
|
||||
**IDENTITY**: The speaker's identity as a technology leader is crucial to understanding their perspective on improving outcomes through better collaboration and feedback.
|
||||
|
||||
**PURPOSE**: The purpose of this talk is to share lessons learned while building a DevOps Center of Excellence, highlighting the importance of prioritization decisions, team dynamics, cognitive load, and leadership support.
|
||||
|
||||
**LESSONS LEARNED**:
|
||||
|
||||
1. **Prioritization**: Leaders should provide context for teams to make strategic decisions quickly.
|
||||
2. **Cognitive Load**: Increasing scope or domain complexity can be taxing; leaders must consider this when making decisions.
|
||||
3. **Leadership Team Dynamics**: The leadership team is a team too; leaders must prioritize collaboration and communication within their own team.
|
||||
|
||||
**PROBLEMS TO SOLVE**:
|
||||
|
||||
1. **Handoff City**: Poll requests, design documents, and support tickets replace actual collaboration.
|
||||
2. **Lack of Shared Context**: Teams struggle to understand each other's work due to disparate tools and systems.
|
||||
3. **High Intelligence Systems**: The speaker envisions a world where systems have high intelligence, reducing context switching and cognitive load.
|
||||
|
||||
**SYSTEM INITIATIVE**: This is a novel devops tooling approach that allows for real-time collaboration, multimodal interaction, and full-fidelity modeling of system resources as digital twins.
|
||||
|
||||
**CALL TO ACTION**: Join the conversation on Discord to learn more about System Initiative, provide feedback, or join the open beta.
|
||||
@ -0,0 +1,26 @@
|
||||
# Day 42 - The North Star: Risk-driven security
|
||||
[](https://www.youtube.com/watch?v=XlF19vL0S9c)
|
||||
|
||||
In summary, the speaker is discussing the importance of threat modeling in software development. Here are the key points:
|
||||
|
||||
1. Threat modeling helps capture the good work already done in security, claim credit for it, and motivate teams. It also accurately reflects the risk by capturing controls that are already in place.
|
||||
2. Business risks should also be considered in threat modeling. Standards and frameworks like AWS Well-Architected, CIS, or NIST can serve as guides.
|
||||
3. Cyber Threat Intelligence (CTI) can be useful but has limitations: it focuses on technology and tells you what has already happened rather than what will happen. Therefore, it should be used cautiously in threat modeling.
|
||||
4. Threat models should be simple yet reflect reality to make them effective communications tools for different audiences within an organization.
|
||||
5. Threat models need to be kept up-to-date to accurately represent the current risk landscape and avoid misrepresenting the risks to the business. Outdated threat models can become a security weakness.
|
||||
|
||||
The speaker also encourages developers to try threat modeling on their projects and offers resources for learning more about threat modeling, such as Adam Shostack's book "Threat Modeling."
|
||||
Here is the summarized content:
|
||||
|
||||
The speaker, Johnny Ties, emphasizes the importance of simplicity in threat modeling. He warns against using CTI (Cyber Threat Intelligence) as a strong indicator of risk, highlighting its limitations and tendency to change frequently. Johnny stresses that threat models should be easy to build, talk about, and read.
|
||||
|
||||
**KEY TAKEAWAYS**
|
||||
|
||||
1. **Simplicity**: The key to effective threat modeling is simplicity. It helps everyone involved in the process.
|
||||
2. **Use it as a Communications tool**: View your threat model as a way to communicate with stakeholders, not just technical teams.
|
||||
3. **Keep it up-to-date**: Threat models that are not kept current can be an Achilles heel and misrepresent risks.
|
||||
|
||||
**ADDITIONAL POINTS**
|
||||
|
||||
* Johnny encourages viewers to try threat modeling with their team and invites feedback.
|
||||
* He mentions Adam Shac's book on threat modeling, which is a great resource for those interested in learning more about the topic.
|
||||
@ -0,0 +1,37 @@
|
||||
# Day 43 - Let's go sidecarless in Ambient Mesh
|
||||
[](https://www.youtube.com/watch?v=T1zJ9tmBkrk)
|
||||
|
||||
# ONE SENTENCE SUMMARY:
|
||||
This video discusses Ambient Mesh, an open-source project that simplifies service mesh architecture by using one proxy per node, reducing cost and complexity, and providing improved security with mTLS and identity management.
|
||||
|
||||
# MAIN POINTS:
|
||||
1. Service mesh addresses challenges in microservice architectures, such as cost, complexity, and performance issues.
|
||||
2. Ambient Mesh is an open-source project that aims to improve service mesh by using one proxy per node instead of one for each container.
|
||||
3. This reduces costs, simplifies operations, and improves performance.
|
||||
4. Ambient Mesh provides out-of-the-box security with mTLS and identity management.
|
||||
5. The architecture uses separate proxies for L3/L4 (Z) and L7 (VPO) to manage traffic.
|
||||
6. The tunneling protocol used in Ambient Mesh is called ONI, which provides L3/L4 capabilities.
|
||||
7. Ambient Mesh is under the Cloud Native Computing Foundation (CNCF) and continues to be improved daily.
|
||||
|
||||
# ADDITIONAL NOTES:
|
||||
- In Ambient Mesh, each node has an identity that is impersonated and creates a secure tunnel for communication between nodes.
|
||||
- The tunneling protocol used in Ambient Mesh is called ONI (Overlay Network Interface).
|
||||
# OUTPUT SECTIONS
|
||||
|
||||
## ONE SENTENCE SUMMARY:
|
||||
The presentation discusses the concept of a service mesh, specifically Ambient Mesh, and its architecture, highlighting its benefits, such as reduced cost, simplified operations, and improved performance.
|
||||
|
||||
## MAIN POINTS:
|
||||
|
||||
1. Service meshes provide secure communication between services.
|
||||
2. Microservices have distributed applications with challenges in observing, securing, and communicating among services.
|
||||
3. Ambient Mesh is an open-source project that simplifies service mesh architecture by having one proxy per node rather than per container.
|
||||
4. It provides reduced cost, simplified operations, and improved performance compared to the sidecar pattern.
|
||||
5. Ambient Mesh uses mutual TLS (mTLS) for secure communication between services.
|
||||
6. The L7 proxy manages layer 7 features, while the L3/L4 proxy handles layer 3 and 4 traffic.
|
||||
7. Zel is responsible for securely connecting and authenticating workloads with CN (Certificate Network).
|
||||
8. The protocol used to connect nodes is called Hone, which provides a secure overlay network.
|
||||
|
||||
## PURPOSE:
|
||||
|
||||
The presentation aims to educate the audience on the benefits and architecture of Ambient Mesh, highlighting its unique features and advantages over traditional service mesh architectures.
|
||||
@ -1,3 +1,49 @@
|
||||
# Day 44 - Exploring Firecracker
|
||||
[](https://www.youtube.com/watch?v=EPMbCUPK7aQ)
|
||||
|
||||
In summary, we discussed the pros and cons of containers and Virtual Machines (VMs), as well as an alternative solution called Firecracker that aims to combine the advantages of both while minimizing their respective disadvantages.
|
||||
|
||||
Pros of containers:
|
||||
- Lightweight (measured in megabytes)
|
||||
- Require fewer resources to deploy, run, and manage
|
||||
- Can spin up quickly (milliseconds to minutes)
|
||||
- High density on a single system (more containers can be hosted compared to VMs)
|
||||
|
||||
Cons of containers:
|
||||
- Newer technology with an evolving ecosystem
|
||||
- Potential security issues due to shared underlying OS
|
||||
- All containers must run the same operating system
|
||||
|
||||
Firecracker aims to provide a secure, fast, and efficient solution by implementing micro VMS using KVM. Firecracker's advantages include:
|
||||
- Minimal device model for enhanced security
|
||||
- Accelerated kernel loading and reduced memory overhead
|
||||
- High density of micro VMs on a single server
|
||||
- Fast startup times (up to 150 micro VMs per second per host)
|
||||
|
||||
When using Firecracker, considerations include:
|
||||
- Implementing scheduling, capacity planning, monitoring, node autoscaling, and high availability features yourself
|
||||
- Suitable for workloads where containers don't work or for short-lived workloads (like Lambda functions)
|
||||
- Potential use cases for students when you don't want to spin up a full VM for training purposes.
|
||||
|
||||
The speaker discusses the concept of "having the best of both worlds" in cloud computing, specifically mentioning containers and virtual machines (VMs). They highlight the limitations of containers, including security concerns and the need for multiple operating systems. VMs, on the other hand, provide better security but are less flexible.
|
||||
|
||||
To address these issues, the speaker introduces Firecracker, a technology that runs micro VMs (MVMs) in user space using KVM (Linux kernel-based virtual machine). MVMs offer fast startup times, low memory overhead, and enhanced security. This allows thousands of MVMs to run on a single machine without compromising performance or security.
|
||||
|
||||
The speaker emphasizes the benefits of Firecracker, including:
|
||||
|
||||
1. **Secure**: MVMs are isolated with common Linux user-space security barriers and have reduced attack surfaces.
|
||||
2. **Fast**: MVMs can be started quickly, with 150 per second per host being a feasible rate.
|
||||
3. **Efficient**: MVMs run with reduced memory overhead, enabling high-density packing on each server.
|
||||
|
||||
However, the speaker notes that using Firecracker requires consideration of additional factors, such as scheduling, capacity planning, monitoring, node autoscaling, and high availability. They also suggest scenarios where Firecracker is particularly useful:
|
||||
|
||||
1. **Short-lived workloads**: MVMs are suitable for short-lived workloads like Lambda functions.
|
||||
2. **Students**: MVMs can be used to provide a lightweight, easily spin-up-and-down environment for students.
|
||||
|
||||
Overall, the speaker aims to demonstrate that Firecracker and MVMs offer an attractive alternative to traditional VMs and containers, providing a secure, fast, and efficient way to run workloads in the cloud.
|
||||
|
||||
|
||||
|
||||
Here are additional resource:
|
||||
|
||||
https://firecracker-microvm.github.io/
|
||||
|
||||
@ -0,0 +1,15 @@
|
||||
# Day 45 - Microsoft DevOps Solutions or how to integrate the best of Azure DevOps and GitHub
|
||||
[](https://www.youtube.com/watch?v=NqGUVOSRe6g)
|
||||
|
||||
In summary, this video demonstrates how to integrate GitHub Actions with an existing Azure DevOps pipeline. The process involves creating a GitHub action that triggers when changes are pushed to the main branch or any other specified branch. This action calls an Azure DevOps pipeline version 1 action from the marketplace, providing necessary information such as project URL, organization name, project name, and personal access token with enough permissions to run build pipelines.
|
||||
|
||||
The video also introduces GitHub Advanced Security for Azure DevOps, which allows users to leverage the same code scanning tool (CodeQL) across both platforms, making it easier to manage development and devops processes. By using these integrations, users can collaborate more effectively within their teams, streamline workflows, and take advantage of the best features from both tools.
|
||||
|
||||
The speaker emphasizes that the goal is not to determine which tool is better but rather to combine the strengths of both platforms to create a seamless development and devops experience. He encourages viewers to explore the other sessions in the event and looks forward to next year's Community Edition.
|
||||
The identity and purpose of this content is:
|
||||
|
||||
**Title:** "GitHub Advanced Security for Azure DevOps"
|
||||
|
||||
**Purpose:** To introduce the integration between GitHub and Azure DevOps, specifically highlighting the use of GitHub Advanced security features for code scanning and vulnerability detection in Azure DevOps pipelines.
|
||||
|
||||
**Identity:** The speaker presents themselves as an expert in content summarization and devops processes, with a focus on integrating GitHub and Azure DevOps tools to streamline workflows and simplify development processes.
|
||||
@ -1,4 +1,5 @@
|
||||
# **AWS Systems Manager**
|
||||
# Day 46 - Mastering AWS Systems Manager: Simplifying Infrastructure Management
|
||||
[](https://www.youtube.com/watch?v=d1ZnS8L85sw)
|
||||
|
||||
AWS Systems Manager is a powerful, fully managed service that simplifies operational tasks for AWS and on-premises resources. This centralized platform empowers DevOps professionals to automate operational processes, maintain compliance, and reduce operational costs effectively.
|
||||
|
||||
|
||||
@ -0,0 +1,36 @@
|
||||
# Day 47 - Azure logic app, low / no code
|
||||
[](https://www.youtube.com/watch?v=pEB4Kp6JHfI)
|
||||
|
||||
It seems like you have successfully created an end-to-end workflow using Azure Logic Apps that processes a grocery receipt image, identifies food items, fetches recipes for those foods, and sends an email with the list of recipes.
|
||||
|
||||
To continue with the next step, follow these instructions:
|
||||
|
||||
1. Save your workflow in your GitHub repository (if you haven't already) so you can access it later.
|
||||
2. To run the workflow, you need to authenticate each connector as mentioned during the explanation:
|
||||
- Azure Blob Storage: You will need to provide authentication for the storage account where the receipt image is stored.
|
||||
- Computer Vision API (OCR): Provide authentication for your Computer Vision resource.
|
||||
- Outlook API: Authenticate with your Outlook account to send emails.
|
||||
3. To test the workflow, upload a new grocery receipt image in the specified storage account.
|
||||
4. Wait for an email with the list of potential recipes based on the items detected in the receipt.
|
||||
5. Review and make changes as needed to improve the workflow or add more features (such as adding JavaScripts, Python functions, etc.).
|
||||
6. Share your experiences, improvements, feedback, and new ideas using Azure Logic Apps in the comments section.
|
||||
7. Enjoy learning and exploring the possibilities of this powerful tool!
|
||||
In this session, we explored creating a workflow using Azure Logic Apps with minimal code knowledge. The goal was to automate a process that takes a receipt as input, extracts relevant information, and sends an email with potential recipes based on the food items purchased.
|
||||
|
||||
The workflow consisted of several steps:
|
||||
|
||||
1. Blob Trigger: A blob trigger was set up to capture new receipts uploaded to a storage account.
|
||||
2. JSON Output: The receipt content was passed through OCR (Optical Character Recognition) and computer vision, which converted the text into a JSON format.
|
||||
3. Schema Classification: The JSON output was then classified using a schema, allowing us to extract specific properties or objects within the JSON.
|
||||
4. Filtering and Looping: An array of food-related texts was created by filtering the original JSON output against a food word list. A loop was used to iterate through each recipe, extracting its name, URL, and image (or thumbnail).
|
||||
5. Email Body: The email body was constructed using variables for the food labels and URLs, listing out potential recipes for the user.
|
||||
|
||||
The final step was sending the email with the recipe list using the Outlook connector.
|
||||
|
||||
Key takeaways from this session include:
|
||||
|
||||
* Azure Logic Apps can be used to simplify workflows without requiring extensive coding knowledge.
|
||||
* The platform provides a range of connectors and actions that can be combined to achieve specific business outcomes.
|
||||
* Creativity and experimentation are encouraged, as users can add their own custom code snippets or integrate with other services.
|
||||
|
||||
The GitHub repository accompanying this session provides the complete code view of the workflow, allowing users to copy and modify it for their own purposes.
|
||||
@ -0,0 +1,28 @@
|
||||
# Day 48 - From Puddings to Platforms: Bringing Ideas to life with ChatGPT
|
||||
[](https://www.youtube.com/watch?v=RQT9c_Cl_-4)
|
||||
|
||||
It sounds like you have built a location-based platform using Google Capture API, Firebase Authentication, Stripe for subscription management, and a custom backend. The platform allows users to submit new locations, which an admin can approve or deny. If approved, the location becomes live on the website and is searchable by other users. Users can also claim a location if it hasn't been claimed yet.
|
||||
|
||||
The backend provides an editor for managing locations, allowing admins to check for new locations, approve or deny requests, edit table entries, save changes, delete records, and add new ones. It also includes a search bar for easily finding specific locations.
|
||||
|
||||
For authenticated users (like the owner of a claimed location), they can edit their location, make changes, save, and delete. The platform is hosted on LightSail and uses GitHub for version control. A script has been created to automatically push and pull changes from Dev into the main environment, effectively acting as CI/CD.
|
||||
|
||||
Stripe integration allows for purchasing verification of locations. Overall, it seems like a well-thought-out and functional platform, leveraging AI and chatbots to help bring your ideas to life. Be sure to check out the website, blog, and podcast you mentioned for more information and insights on using generative AI in 2024 and beyond!
|
||||
You've successfully summarized your content, leveraging Safari's responsive design to showcase differences between desktop and mobile views. Your summary highlights the key features of your application, including:
|
||||
|
||||
1. Purpose: The purpose is to demonstrate the capabilities of generative AI in platform engineering.
|
||||
|
||||
Your summary covers the following topics:
|
||||
|
||||
1. Front-end and back-end development:
|
||||
* Crowdsourcing locations and adding them to the database
|
||||
* Allowing users to claim and manage their own locations
|
||||
* Integration with Stripe for subscription management
|
||||
2. Firebase authentication:
|
||||
* Creating user accounts and linking them to Stripe subscriptions
|
||||
3. Hosting and deployment:
|
||||
* Deploying the application on Light Sail, a cloud-based platform
|
||||
4. GitHub integration:
|
||||
* Using GitHub as a repository for version control and continuous integration/continuous deployment (CI/CD)
|
||||
5. End-to-end development process:
|
||||
* From idea generation with ChatGPT to code manipulation, testing, and deployment
|
||||
@ -0,0 +1,23 @@
|
||||
# Day 49 - From Confusion To Clarity: Gherkin & Specflow Ensures Clear Requirements and Bug-Free Apps
|
||||
[](https://www.youtube.com/watch?v=aJHLnATd_MA)
|
||||
|
||||
You have created a custom web application test using a WebApplicationFactory and SpecFlow, along with an in-memory repository. To ensure that duplicate jokes are not added to the database, you wrote a test scenario that checks if a joke already exists before creating it again.
|
||||
|
||||
When encountering a situation where a database is required for testing, you demonstrated how to spin up a container using Docker as part of the test pipeline, allowing you to use an isolated test database during your tests. By overriding the connection string in the configureWebHost method, you can point to the test container rather than your other containers.
|
||||
|
||||
Finally, you provided insight into exceptions testing and how to utilize Gherkin and SpecFlow for acceptance testing in an automated fashion. Thank you for sharing this interesting topic! If you have any questions or need further clarification, feel free to ask!
|
||||
The topic of identity and purpose!
|
||||
|
||||
As an expert content summarizer, I've taken the liberty to condense your presentation on exceptions testing, Girkin, and SpecFlow. Here's a summary:
|
||||
|
||||
**Identity**: You created two identical jokes in the database, leveraging the same method for creating a joke, but with different steps: (1) creating the joke again and (2) ensuring that the ID of the new joke is the same as the original joke.
|
||||
|
||||
**Purpose**: To demonstrate the importance of exceptions testing in handling duplicate entries in your repository. You showed how to create a simple solution using SpecFlow to test if a joke already exists, preventing the creation of duplicates.
|
||||
|
||||
**Girkin and SpecFlow**: You introduced Girkin (Girona) as an in-memory repository and demonstrated its use in creating a basic example of exceptions testing with SpecFlow. You also discussed how to handle internal dependencies, such as spinning up containers for databases or other services, as part of your test pipeline.
|
||||
|
||||
**Key takeaways**:
|
||||
|
||||
1. Exceptions testing is crucial in handling duplicate entries in your repository.
|
||||
2. Girkin and SpecFlow can be used together to create acceptance tests that simulate real-world scenarios.
|
||||
3. Spinning up containers as part of your test pipeline can help simplify the process of integrating with external services or databases.
|
||||
@ -0,0 +1,46 @@
|
||||
# Day 50 - State of Cloud Native 2024
|
||||
[](https://www.youtube.com/watch?v=63qRo4GzJwE)
|
||||
|
||||
In summary, the state of cloud native in 2024 will witness significant advancements across several key areas:
|
||||
|
||||
1. Platform Engineering: The next iteration of DevOps, platform engineering aims to standardize tooling and reduce complexity by providing self-service APIs and UIs for developers. This approach minimizes duplication of setups, improves cost reduction, finops, and enhances security compliance across projects within an organization.
|
||||
|
||||
2. Sustainability: WebAssembly will grow in the cloud native ecosystem, becoming mainstream for server-side web applications and Cloud WebAssembly with Kubernetes runtime as a key enabler. There are ongoing works around extending the WebAssembly ecosystem, making it more versatile and mainstream in 2024.
|
||||
|
||||
3. Generative AI: In 2023, generative AI gained significant momentum, with projects like KGPD being accepted into CNCF sandbox. In 2024, we will see more innovations, adoption, and ease of deployment within the AI ecosystem, including end-to-end platforms for developing, training, deploying, and managing machine learning workloads. GPU sharing, smaller providers offering more interesting services in the AI space, and EVF/AI integrations are some trends to watch out for.
|
||||
|
||||
4. Observability: There will be a growing trend of observability startups incorporating AI to auto-detect and fix issues related to Kubernetes and cloud native environments. This will help organizations maintain their cloud native infrastructure more efficiently.
|
||||
|
||||
It is essential to focus on these areas in 2024 to stay updated, get involved, and capitalize on the opportunities they present. Share your thoughts on which aspects you believe will see the most adoption, innovation, or production use cases in the comments below.
|
||||
|
||||
**IDENTITY and PURPOSE**
|
||||
|
||||
You discussed how platform engineering can simplify the process of managing multiple projects, teams, and tools within an organization. By having a single platform, developers can request specific resources (e.g., clusters) without needing to understand the underlying infrastructure or Cloud provider. This standardization of tooling across the organization is made possible by the platform engineering team's decision-making based on security best practices, compliance, and tooling maturity.
|
||||
|
||||
**PLATFORM ENGINEERING**
|
||||
|
||||
You highlighted the importance of platform engineering in 2024, noting that it will lead to:
|
||||
|
||||
* Single-platform management for multiple projects
|
||||
* Standardization of tooling across the organization
|
||||
* Cost reduction through self-serving APIs and UIs
|
||||
* FinOps (financial operations) integration
|
||||
|
||||
**CLOUD NATIVE and AI**
|
||||
|
||||
You emphasized the growing importance of cloud native and AI in 2024, mentioning:
|
||||
|
||||
* Generative AI's mainstream adoption in 2023
|
||||
* Kubernetes' role as a foundation for machine learning workloads
|
||||
* The increasing number of projects and innovations in the AI space
|
||||
* End-to-end platforms for developing, training, deploying, and managing machine learning models
|
||||
|
||||
**SUSTAINABILITY**
|
||||
|
||||
You touched on sustainability, mentioning:
|
||||
|
||||
* WebAssembly's growth and adoption in the cloud native ecosystem
|
||||
* Its potential to become a mainstream technology for server-side development
|
||||
* The importance of observing startups incorporating AI to auto-detect and auto-fix issues related to Kubernetes
|
||||
|
||||
In summary, your key points can be grouped into four main areas: Platform Engineering, Cloud Native, AI, and Sustainability. Each area is expected to see significant growth, innovation, and adoption in 2024.
|
||||
@ -0,0 +1,40 @@
|
||||
# Day 51 - DevOps on Windows
|
||||
[](https://www.youtube.com/watch?v=_mKToogk3lo)
|
||||
|
||||
In this explanation, you're discussing various tools and environments available for developers using Visual Studio Code (VS Code) on Windows. Here's a summary of the key points:
|
||||
|
||||
1. VS Code allows you to connect directly to different environments such as WSL, Dev Containers, Code Spaces, and SSH servers.
|
||||
2. Git Bash serves as a translation layer between the user's local machine (Windows) and Linux commands, but it doesn't provide access to the Linux file system.
|
||||
3. Git is accessible by default in VS Code with Git Bash, allowing you to perform git commands natively on Windows while targeting repositories on your Linux file system via WSL.
|
||||
4. It's essential to work primarily within the WSL file system to avoid performance issues when working with large files or complex operations.
|
||||
5. VS Code can be used to edit and save files directly from WSL, with extensions like Preview helping you interact with the files in a more visual way.
|
||||
6. Developers also have options for container management tools such as Docker Desktop, Podman Desktop, Rancher Desktop, and Finch (based on kubectl, podman, and nerdctl).
|
||||
7. Finch is unique because it shares tooling with Rancher Desktop and leverages Lima, a tool originally developed for macOS, to create container environments on Windows using WSL2 as the driver.
|
||||
8. Developers can use these tools to run containerized applications and orchestrate them using kubernetes or open shifts.
|
||||
|
||||
Overall, the talk emphasizes the growing support for devops tools on Windows platforms and encourages developers to explore these tools further for their projects.
|
||||
Here's a summary of the content:
|
||||
|
||||
**Setting up the Environment**
|
||||
|
||||
To start, the speaker sets up their Visual Studio Code (VSCode) with SSH plugin, allowing them to connect remotely to environments and develop there. They also use Git Bash as a translation layer, which allows them to use standard Linux commands on Windows.
|
||||
|
||||
**Git and GitHub Desktop**
|
||||
|
||||
The speaker highlights the importance of having access to Git commands directly from VSCode or PowerShell. They also mention using GitHub desktop, which is a visual tool that simplifies many Git operations.
|
||||
|
||||
**Working with WSL (Windows Subsystem for Linux)**
|
||||
|
||||
The speaker explains that WSL allows them to run Linux distributions natively on Windows. This enables the use of various tools and frameworks, including containers and Kubernetes. However, they emphasize the importance of working within the WSL file system to avoid performance issues.
|
||||
|
||||
**Containers and Kubernetes**
|
||||
|
||||
To support containerization, the speaker mentions three options: Docker desktop, Rancher desktop, and Podman desktop. These tools allow for running containers and managing them through Kubernetes or other runtimes.
|
||||
|
||||
**Finch and Lima**
|
||||
|
||||
The final tool mentioned is Finch, which was created by the Azure team to provide a Windows-based solution for working with containers and Kubernetes. The speaker notes that Finch uses Lima as its driver on Mac OS and has been ported to Windows using WSL2.
|
||||
|
||||
**Conclusion**
|
||||
|
||||
The talk concludes by emphasizing the importance of setting up a development environment on Windows and exploring the various tools available, including Git, GitHub desktop, WSL, Docker, Rancher, Podman, and Finch. The speaker encourages continued learning and exploration in the DevOps space.
|
||||
@ -0,0 +1,44 @@
|
||||
# Day 52 - Creating a custom Dev Container for your GitHub Codespace to start with Terraform on Azure
|
||||
[](https://www.youtube.com/watch?v=fTsaj7kqOvs)
|
||||
|
||||
# ONE SENTENCE SUMMARY:
|
||||
Patrick K demonstrates how to create a Dev container for a GitHub repository with Terraform and the Azure CLI, using Visual Studio Code and a Docker file and Dev container JSON file.
|
||||
|
||||
# MAIN POINTS:
|
||||
1. Create an empty repository on GitHub named `Asia terraform code space`.
|
||||
2. Inside the repository, create a `dev container` folder with two files: `dockerfile` and `devcontainer.json`.
|
||||
3. In the `dockerfile`, install the Asia CLI, Terraform, and other necessary tools using a base image.
|
||||
4. Use the `devcontainer.json` to configure the environment for the code space, referencing the `dockerfile`.
|
||||
5. Commit and push the changes to the main branch of the repository.
|
||||
6. Use Visual Studio Code's Remote Explorer extension to create a new code space from the repository.
|
||||
7. The Dev container will be built and run in the background on a virtual machine.
|
||||
8. Once the code space is finished, Terraform and the Asia CLI should be available within it.
|
||||
9. To stop the Dev container, click 'disconnect' when you no longer need it.
|
||||
10. Rebuild the container to extend it with new tools as needed.
|
||||
|
||||
# TAKEAWAYS:
|
||||
1. You can create a Dev container for your GitHub code space using Visual Studio Code and two files: `dockerfile` and `devcontainer.json`.
|
||||
2. The `dockerfile` installs necessary tools like the Asia CLI and Terraform, while the `devcontainer.json` configures the environment for the code space.
|
||||
3. Once you have created the Dev container, you can use it to work with Terraform and the Asia CLI within your GitHub code space.
|
||||
4. To start working with the Dev container, create a new terminal and check if Terraform and the Asia CLI are available.
|
||||
5. Remember to stop the Dev container when you no longer need it to save resources, and rebuild it as needed to extend its functionality.
|
||||
Here is the output:
|
||||
|
||||
# ONE SENTENCE SUMMARY:
|
||||
Create a Dev container for your GitHub code space to work with Terraform and the AWS CLI by creating a Docker file and a devcontainer.json file.
|
||||
|
||||
# MAIN POINTS:
|
||||
|
||||
1. Create an empty repository named Azure terraform code space.
|
||||
2. Create two files: a Docker file and a devcontainer.json file, inside a dev-container directory.
|
||||
3. Define the base image and install the necessary tools, including AWS CLI and Terraform.
|
||||
4. Configure the devcontainer.json file to set up the environment for your code space.
|
||||
5. Push the changes to the main branch of your repository.
|
||||
|
||||
# TAKEAWAYS:
|
||||
|
||||
1. Create a new Dev container for your GitHub code space using Visual Studio Code.
|
||||
2. Use the Docker file to install necessary tools, including AWS CLI and Terraform.
|
||||
3. Configure the devcontainer.json file to set up the environment for your code space.
|
||||
4. Push changes to the main branch of your repository to create the code space.
|
||||
5. Start working with Terraform and the AWS CLI in your code space using the Dev container.
|
||||
@ -0,0 +1,40 @@
|
||||
# Day 53 - Gickup - Keep your repositories safe
|
||||
[](https://www.youtube.com/watch?v=hKB3XY7oMgo)
|
||||
|
||||
# ONE SENTENCE SUMMARY:
|
||||
Andy presented Gickup, a tool for backing up Git repositories across various platforms like GitHub, GitLab, Bitbucket, etc., written in Go. He explained its usage, demonstrated its functionality, and showcased its ability to restore deleted repositories.
|
||||
|
||||
# MAIN POINTS:
|
||||
1. Gickup is a tool written by Andy for backing up Git repositories.
|
||||
2. It supports GitHub, GitLab, Bitbucket, SourceForge, local repositories, and any type of Git repository as long as you can provide access credentials.
|
||||
3. Automation is simple; once configured, it takes care of everything.
|
||||
4. It can be run using pre-compiled binaries, Homebrew, Docker, Arch User Repository (AUR), or NYX.
|
||||
5. Gickup connects to the API of the host service and grabs the repositories you want to back up.
|
||||
6. You define a source (like GitHub) and specify a destination, which could be local backup, another Git hoster, or a mirror.
|
||||
7. The configuration is in YAML, where you define the source, destination, structured format for the backup, and whether to create an organization if it doesn't exist.
|
||||
8. Demonstration included backing up and restoring repositories, mirroring repositories to another Git hoster, and handling accidental repository deletions.
|
||||
9. Gickup can be kept up-to-date through the presenter's social media accounts or QR code linked to his GitHub account.
|
||||
|
||||
|
||||
# ONE SENTENCE SUMMARY:
|
||||
Gickup is a tool written in Go, designed to backup and restore Git repositories, allowing for simple automation and secure backups.
|
||||
|
||||
# MAIN POINTS:
|
||||
|
||||
1. Gickup is a tool that backs up Git repositories, supporting multiple hosting platforms.
|
||||
2. It can be run using pre-compiled binaries, Homebrew, Docker, or AUR.
|
||||
3. Gickup connects to the API of the hoster, grabbing all desired repositories and their contents.
|
||||
4. Configuration is done in YAML, defining sources, destinations, and backup options.
|
||||
5. Local backups can be created, with an optional structured directory layout.
|
||||
6. Mirroring to another hosting platform is also possible, allowing for easy repository management.
|
||||
7. Gickup provides a simple automation solution for backing up Git repositories.
|
||||
|
||||
# TAKEAWAYS:
|
||||
|
||||
1. Use Gickup to automate the process of backing up your Git repositories.
|
||||
2. Gickup supports multiple hosting platforms and allows for secure backups.
|
||||
3. Configure Gickup using YAML files to define sources, destinations, and backup options.
|
||||
4. Create local backups or mirror repositories to another hosting platform for easy management.
|
||||
5. Restore deleted repositories by recreating the repository, grabbing the origin, and pushing changes.
|
||||
6. Use Gickup to keep your Git repositories safe and organized.
|
||||
7. Consider using Gickup as a part of your DevOps workflow.
|
||||
@ -0,0 +1,40 @@
|
||||
# Day 54 - Mastering AWS OpenSearch: Terraform Provisioning and Cost Efficiency Series
|
||||
[](https://www.youtube.com/watch?v=GYrCbUqHPi4)
|
||||
|
||||
# ONE SENTENCE SUMMARY:
|
||||
This session demonstrates how to ingest logs into AWS OpenSearch using a LockStash agent, discussing cost optimization techniques and providing instructions on setting up the environment.
|
||||
|
||||
# MAIN POINTS:
|
||||
1. The content is about ingesting logs into AWS OpenSearch using LockStash.
|
||||
2. A provision search cluster and a LockStash agent are used for log collection.
|
||||
3. The design includes two E2 instances in different availability zones, with an OpenSearch cluster deployed on the same VPC.
|
||||
4. The LockStash agent sends logs to the OpenSearch cluster for processing.
|
||||
5. A sample pipeline is provided to input and output the desired logs.
|
||||
6. Terraform is used to provision the AWS OpenSearch cluster.
|
||||
7. An Amazon EC2 instance is created for the OpenSearch cluster with specific configurations.
|
||||
8. The code demonstrates creating an OpenSearch cluster in a specified region (US East).
|
||||
9. Index life cycle policy is introduced as a cost optimization technique.
|
||||
10. The index life cycle policy deletes older indexes, and there are options to customize the policy based on requirements.
|
||||
|
||||
# ADDITIONAL NOTES:
|
||||
- LinkedIn ID for further questions or contact.
|
||||
# ONE SENTENCE SUMMARY:
|
||||
|
||||
AWS Open Search provides a scalable and cost-effective solution for ingesting logs, with features like provisioned clusters, data collection engines (Lock Stash), and index life cycle policies to manage storage and costs.
|
||||
|
||||
# MAIN POINTS:
|
||||
|
||||
1. AWS Open Search is used to ingest logs from various sources.
|
||||
2. A Lock Stash agent is used to send logs to the Open Search cluster in real-time.
|
||||
3. The Lock Stash pipeline includes input, output, and debug options.
|
||||
4. Provisioning an Open Search cluster using Terraform involves creating a new region, cluster name, version, instance type, and EBS volume size.
|
||||
5. Installing the Lock Stash agent requires downloading and extracting the agent, then configuring it to send logs to the Open Search cluster.
|
||||
6. Index life cycle policies are used to manage storage and costs by deleting older indexes.
|
||||
|
||||
# TAKEAWAYS:
|
||||
|
||||
1. AWS Open Search is a scalable solution for ingesting logs from various sources.
|
||||
2. Lock Stash agents can be used to send logs in real-time to an Open Search cluster.
|
||||
3. Provisioning and configuring an Open Search cluster requires attention to detail, including region, cluster name, version, instance type, and EBS volume size.
|
||||
4. Index life cycle policies are essential for managing storage and costs by deleting older indexes.
|
||||
5. Monitoring and optimizing log ingestion can help reduce costs and improve performance.
|
||||
@ -0,0 +1,35 @@
|
||||
# Day 55 - Bringing Together IaC and CM with Terraform Provider for Ansible
|
||||
[](https://www.youtube.com/watch?v=dKrYUikDgzU)
|
||||
|
||||
In this explanation, a workflow that uses Terraform and Ansible to dynamically provision infrastructure and configure web servers. Here's a simplified breakdown of the process:
|
||||
|
||||
1. Use the external IP address of the newly created web server (web VM) to define dynamically your Ansible inventory file. This is done by mapping the Playbooks against hosts in the 'web' group, which is defined in the inventory metadata. The metadata also includes details about the user for SSH, SSH key, and Python version.
|
||||
|
||||
2. Run an Ansible command (`ansible-inventory -g graph`) to visualize the inventory file as a graph. This helps debug information and displays variables like the user being used to connect to the host.
|
||||
|
||||
3. Execute the specified Playbook (asle Playbook) using Ansible against the hosts in the 'web' group. The Playbook will install, start, clean up, and deploy an app from GitHub onto the web servers.
|
||||
|
||||
4. Validate the Terraform code syntax with `terraplan validate`. Before actually deploying the infrastructure, it's a good idea to check the Terraform State file to make sure there are no existing resources that could interfere with the deployment.
|
||||
|
||||
5. Run the `terraform plan` command to let Terraform analyze what needs to be created and deployed without executing anything. If the analysis looks correct, run `terraform apply` to start deploying the infrastructure.
|
||||
|
||||
6. The Terraform workflow will create resources like a VPC subnet, firewall rules, a computing instance (web VM), and an Ansible host with its external IP address captured for connectivity. It will also create an URL using the output of Terraform to display the deployed application from GitHub.
|
||||
|
||||
7. Finally, check that the application works by accessing it through the generated URL. If everything is working correctly, you should see the application with the title of the session.
|
||||
|
||||
8. After the deployment, the Terraform State file will be populated with information about the infrastructure created. Be aware that the Terraform State file contains sensitive information; there are discussions on how to protect it and encrypt it when needed.
|
||||
**IDENTITY and PURPOSE**
|
||||
|
||||
The speaker is an expert in content summarization, debugging information, and executing Playbooks. They are about to run a Playbook called "ASLE" that will provision infrastructure using Terraform and configure hosts with Ansible.
|
||||
|
||||
The speaker starts by mentioning the importance of binding Terraform and Ansible together, which is done through the inventory file. The ASLE Playbook defines which group of hosts (web) to use and what tasks to execute. These tasks include ensuring the existence of a specific package (engine X), starting it, and cleaning up by removing default files.
|
||||
|
||||
The speaker then validates the Terraform code using `terraform validate` and ensures that the syntax is correct. They also run `terraform plan` to analyze what resources need to be created, but do not execute anything yet.
|
||||
|
||||
After running the plan, the speaker applies the plan using `terraform apply`, which starts deploying the infrastructure. The deployment process creates a VPC subnet, firewall rules, an instance, and other resources.
|
||||
|
||||
Once the deployment is complete, the speaker runs the Ansible playbook, which executes the tasks defined in the Playbook. These tasks include installing engine X, starting it, removing default files, downloading a web page from GitHub, and configuring the infrastructure.
|
||||
|
||||
The speaker also demonstrates how to use Ansible's `graph` command to present the inventory in a graphical mode. Finally, they run the Ansible playbook again to execute the tasks defined in the Playbook.
|
||||
|
||||
Throughout the session, the speaker emphasizes the importance of binding Terraform and Ansible together for dynamic provisioning of infrastructure and configuration management.
|
||||
@ -0,0 +1,47 @@
|
||||
# Day 56 - Automated database deployment within the DevOps process
|
||||
[](https://www.youtube.com/watch?v=LOEaKrcZH_8)
|
||||
|
||||
To baseline local tests or integration tests within your pipelines, you can use Docker containers to create an initial database state. Here's how it works:
|
||||
|
||||
1. Spin up your Docker container with the SQL Server running.
|
||||
2. Deploy your schema, insert test data, and set up the initial baseline.
|
||||
3. Commit the Docker container with a tag (e.g., version 001) containing the initial state of the database.
|
||||
4. Run tests using the tagged Docker container for consistent testing results.
|
||||
5. If needed, create additional containers for different versions or configurations.
|
||||
6. For testing purposes, run a Docker container with the desired tag (e.g., version 001) to have a pre-configured database environment.
|
||||
7. To make things more manageable, you can build custom CLI tools around SQL Package or create your own command line application for business logic execution.
|
||||
8. Use containers for DB schema deployment instead of deploying SQL Packager to agents.
|
||||
9. Shift the database deployment logic from the pipeline to the application package (for example, using Kubernetes).
|
||||
- Add an init container that blocks the application container until the migration is done.
|
||||
- Create a Helm chart with your application container and the migration container as an init container.
|
||||
- The init container listens for the success of the migration container, which updates the database schema before deploying the application containers.
|
||||
10. In summary:
|
||||
- Treat your database as code.
|
||||
- Automate database schema changes within pipelines (no manual schema changes in production).
|
||||
- Handle corner cases with custom migration scripts.
|
||||
- Package the database deployment into your application package to simplify pipelines (if possible). If not, keep the database deployment within your pipeline.
|
||||
Here's a summary of the content:
|
||||
|
||||
**Identity and Purpose**
|
||||
|
||||
The speaker discusses the importance of integrating database development into the software development process, treating the database as code. They emphasize that manual schema changes should never occur during deployment.
|
||||
|
||||
**Using Containers for Database Schema Deployment**
|
||||
|
||||
The speaker explains how containers can be used to simplify database schema deployment. They demonstrate how to use Docker containers to deploy and test different database versions, making it easier to maintain consistency across environments.
|
||||
|
||||
**Baselining for Local Tests and Integration Tests**
|
||||
|
||||
The speaker shows how to create a baseline of the initial database state using Docker containers. This allows for easy testing and resetting of the database to its original state.
|
||||
|
||||
**Autonomous Deployment or Self-Contained Deployment**
|
||||
|
||||
The speaker discusses how to package SQL packager into a container, allowing for autonomous deployment or self-contained deployment. They explain how this can be achieved in Kubernetes using Helm deployments.
|
||||
|
||||
**Shifting Database Deployment Logic from Pipelines to Application Packages**
|
||||
|
||||
The speaker shows an example of shifting database deployment logic from the pipeline to the application package using Helm releases. This simplifies the pipeline and makes it easier to manage.
|
||||
|
||||
**Recap**
|
||||
|
||||
The speaker summarizes the key points, emphasizing the importance of treating databases as code, automating schema changes, handling corner cases with custom migration scripts, and packaging database deployment into application packages or using pipelines for deployment.
|
||||
@ -0,0 +1,28 @@
|
||||
# Day 57 - A practical guide to Test-Driven Development of infrastructure code
|
||||
[](https://www.youtube.com/watch?v=VoeQWkboSUQ)
|
||||
|
||||
A session describing a CI/CD pipeline in GitHub Actions that uses various tools such as Terraform, Bicep, Azure Policies (PS Rule), Snyk, and Pester to validate the security, compliance, and functionality of infrastructure code before deploying it to the actual environment. Here's a summary of the steps you mentioned:
|
||||
|
||||
1. Run tests locally using tools like Terraform, Bicep, and Azure Policies (PS Rule) before committing the code. This ensures that the changes are secure, compliant, and follow best practices.
|
||||
2. In the CI/CD pipeline, use a workflow file in GitHub to combine these tests. The workflow includes jobs for linting, validation using pre-flight validation with ARM deploy action, running Azure Policies (PS Rule), Snyk, and Pester tests.
|
||||
3. Use the built-in GitHub actions to run these tests in the pipeline. For example, use the Azure PS rule action to assert against specific Azure Policy modules, provide input path, output format, and file name.
|
||||
4. Approve the test results before deploying changes to the environment. This ensures that it is safe to push the deploy button.
|
||||
5. After deployment, run tests to verify if the deployment succeeded as intended, and if deployed resources have the right properties as declared in the code. Use tools like BenchPress (based on Pasta) or Pester to call the actual deployed resources and assert against their properties.
|
||||
6. Optionally, use infrastructure testing tools such as smoke tests to validate the functionality of the deployed resources (e.g., a website).
|
||||
7. To make it easier to install and configure these tools, consider using a Dev Container in Visual Studio Code. This allows you to define what tools should be pre-installed in the container, making it easy to set up an environment with all the necessary tools for developing infrastructure code.
|
||||
|
||||
Overall, this is a great approach to ensure that your infrastructure code is secure, compliant, and functional before deploying it to the actual environment. Thanks for sharing this valuable information!
|
||||
|
||||
1. **Azure DevOps**: The speaker discussed using Azure Pipelines to automate infrastructure testing and deployment.
|
||||
2. **Security Testing**: They mentioned using Snak to run security tests in a continuous integration pipeline, allowing for automated testing and deployment.
|
||||
3. **Deployment**: The speaker emphasized the importance of testing and verifying the actual deployment before pushing changes to production.
|
||||
4. **Testing Types**: They introduced three types of tests: unit tests (Pester), infrastructure tests (BenchPress or Pesto), and smoke tests.
|
||||
5. **Dev Container**: The speaker discussed using a Dev Container in Visual Studio Code to pre-configure and pre-install tools for developing Azure infrastructure code.
|
||||
|
||||
These key takeaways summarize the main topics and ideas presented by the speaker:
|
||||
|
||||
* Automating infrastructure testing and deployment with Azure Pipelines
|
||||
* Leveraging Snak for security testing in CI pipelines
|
||||
* Emphasizing the importance of verifying actual deployments before pushing changes to production
|
||||
* Introducing different types of tests (unit, infrastructure, smoke) for ensuring the quality of infrastructure code
|
||||
* Utilizing Dev Containers in Visual Studio Code to streamline development and deployment processes
|
||||
@ -1,4 +1,5 @@
|
||||
# The Reverse Technology Thrust
|
||||
# Day 58 - The Reverse Technology Thrust
|
||||
[](https://www.youtube.com/watch?v=tmwjQnSTE5k)
|
||||
|
||||

|
||||
|
||||
|
||||
@ -0,0 +1,57 @@
|
||||
# Day 59 - Continuous Delivery pipelines for cloud infrastructure
|
||||
[](https://www.youtube.com/watch?v=L8hqM3Y5pTo)
|
||||
|
||||
The three principles of Continuous Delivery for Infrastructure Code are:
|
||||
|
||||
1. Everything is code, and everything is in version control: This means that all infrastructure components are treated as code, stored in a version control system, and can be easily tracked, managed, and audited.
|
||||
|
||||
2. Continuously test and deliver all the work in progress: This principle emphasizes the importance of testing every change before it's deployed to production, ensuring that the infrastructure is always stable and functional. It also encourages automating the deployment process to reduce manual errors and improve efficiency.
|
||||
|
||||
3. Work in small simple pieces that you can change independently: This principle suggests dividing infrastructure components into smaller, independent modules or stacks that can be changed without affecting other parts of the infrastructure. This reduces complexity, shortens feedback cycles, and allows for more effective management of permissions and resources.
|
||||
|
||||
In terms of organizing technology capabilities within an organization, these are usually structured in a layered approach, with business capabilities at the top, technology capabilities in the middle, and infrastructure resources at the bottom. Technology capabilities are further broken down into infrastructure stacks, which are collections of cloud infrastructure resources managed together as a group.
|
||||
|
||||
Examples of infrastructure stacks include a Kubernetes cluster with node groups and a load balancer, a Key Vault for managing secrets, and a Virtual Private Cloud (VPC) network. Good criteria for slicing infrastructure stacks include team or application boundaries, change frequency, permission boundaries, and technical capabilities.
|
||||
|
||||
To get started with infrastructure automation, teams can implement what is called the "Walking Skeleton" approach, which involves starting simple and gradually improving over time. This means setting up a basic pipeline that runs a Terraform apply on a development or test stage in the initial iteration, then iterating and improving upon it as the project progresses.
|
||||
|
||||
Challenges faced when automating infrastructure code include blast radius (the potential damage a given change could make to the infrastructure) and disaster recovery (the ability to recover from a state where all infrastructure code has been lost). To address these challenges, teams should regularly practice deploying from scratch, design their pipelines to test both spinning up infrastructure from zero and applying changes to the existing infrastructure, and ensure that their infrastructure code is modular and independent.
|
||||
|
||||
Recommended resources for diving deeper into this topic include the book "Infrastructure as Code" by Kief Morris, which provides practical guidance on implementing Continuous Delivery for infrastructure.
|
||||
Here is the summary of the presentation:
|
||||
|
||||
**IDENTITY and PURPOSE**
|
||||
|
||||
The presenter discussed how to bring together AWS and Google Cloud platforms, specifically focusing on building technology capabilities. They introduced the concept of "infrastructure Stacks" - collections of cloud infrastructure resources managed together as a group.
|
||||
|
||||
The presenter then presented criteria for slicing infrastructure stacks:
|
||||
|
||||
1. Team or application or domain boundaries
|
||||
2. Change frequency (e.g., updating Kubernetes clusters more frequently than VPCs)
|
||||
3. Permission boundaries (to provide least privileges and prevent over-privileging)
|
||||
4. Technical capabilities (e.g., building a kubernetes cluster as one capability)
|
||||
|
||||
The presenter emphasized the importance of starting with infrastructure automation early in a project, using a "walking skeleton" approach to reduce complexity and improve feedback cycles.
|
||||
|
||||
**CHALLENGES**
|
||||
|
||||
Two challenges were highlighted:
|
||||
|
||||
1. Blast radius: the potential damage a given change could make to a system
|
||||
2. Immutable deployments: replacing old container images with new ones, making it difficult to practice Disaster Recovery
|
||||
|
||||
The presenter recommended rethinking how infrastructure changes are handled in a pipeline to include testing from zero to latest version.
|
||||
|
||||
**SUMMARY**
|
||||
|
||||
The presentation concluded by summarizing the three principles of continuous delivery for infrastructure:
|
||||
|
||||
1. Everything is code and everything is inversion control
|
||||
2. Continuously test and deliver all work in progress
|
||||
3. Work in small, simple pieces that can be changed independently
|
||||
|
||||
The presenter also mentioned the importance of promoting a code base that does not change throughout the individual stages of the pipeline.
|
||||
|
||||
**FURTHER READING**
|
||||
|
||||
The presenter recommended checking out the book "Infrastructure as Code" by ke Morris (currently working on the Third Edition) on O'Reilly.
|
||||
@ -1,4 +1,42 @@
|
||||
# Migrating a monolith to Cloud-Native and the stumbling blocks that you don’t know about
|
||||
# Day 60 - Migrating a monolith to Cloud-Native and the stumbling blocks that you don’t know about
|
||||
[](https://www.youtube.com/watch?v=Bhr-lxHvWB0)
|
||||
|
||||
In transitioning to the cloud native space, there are concerns about cost savings and financial management. Traditionally, capital expenditures (CapEx) allow for depreciation write-offs, which is beneficial for companies, especially at larger scales. However, with cloud services often paid through a credit card, it becomes challenging to depreciate Operational Expenditures (OpEx). This can lead to problems for CFOs as they require predictability and projectability in their financial planning.
|
||||
|
||||
To address these concerns, it is essential to have open discussions with decision-makers about the nature of cloud native solutions and how leasing hardware rather than owning it may affect spending patterns. You will find that costs can fluctuate significantly from month to month due to factors like scaling up or down resources based on demand.
|
||||
|
||||
Here are some steps you can take to improve your chances of success in the cloud native space:
|
||||
|
||||
1. Assess the current state of your applications and containers: Determine if your application was truly containerized, or if it has just been wrapped using a pod. This is crucial because many organizations still follow an outdated approach to containerization based on early promises from Docker.
|
||||
|
||||
2. Prioritize optimization over features: Encourage your teams to focus on optimizing existing applications rather than adding new features, as this will help drive efficiency and save engineering time.
|
||||
|
||||
3. Build future cloud native applications from the ground up: If possible, design new cloud-native applications with the appropriate tools for optimal performance. This will prevent you from going into the red while trying to adapt an existing application to fit a cloud native environment.
|
||||
|
||||
4. Use the right tool for the job: Just as using a saw when you need a hammer won't work effectively, migrating an application without careful consideration may not be ideal or successful. Ensure that your team understands the specific needs of the application and chooses the appropriate cloud native solution accordingly.
|
||||
|
||||
**Main Themes:**
|
||||
|
||||
1. **Tribal Knowledge**: The importance of sharing knowledge across teams and microservices in a cloud-native space.
|
||||
2. **Monitoring and Visibility**: Recognizing that multiple monitoring applications are needed for different teams and perspectives.
|
||||
3. **Cloud Native Economics**: Understanding the differences between data center and cloud native economics, including Opex vs. Capex and the need for projectability.
|
||||
4. **Containerization**: The importance of truly containerizing an app rather than just wrapping a pod and moving on.
|
||||
|
||||
**Purpose:**
|
||||
|
||||
The purpose of this conversation seems to be sharing lessons learned from experience in the cloud-native space, highlighting the importance of:
|
||||
|
||||
1. Recognizing tribal knowledge and sharing it across teams.
|
||||
2. Adapting to the changing landscape of monitoring and visibility in cloud-native environments.
|
||||
3. Understanding the unique economics of cloud native and its implications for decision-making.
|
||||
4. Emphasizing the need for true containerization and optimization rather than just wrapping a pod.
|
||||
|
||||
**Takeaways:**
|
||||
|
||||
1. Share knowledge across teams and microservices to avoid silos.
|
||||
2. Be prepared for multiple monitoring applications in cloud-native environments.
|
||||
3. Understand the differences between data center and cloud native economics.
|
||||
4. Prioritize true containerization and optimization over quick fixes.
|
||||
|
||||
By: JJ Asghar
|
||||
Slides: [here](https://docs.google.com/presentation/d/1Nyh_rfB-P4C1uQI6E42qHMEfAj-ZTXGDVKaw1Em8H5g/edit?usp=sharing)
|
||||
|
||||
@ -0,0 +1,45 @@
|
||||
# Day 61 - Demystifying Modernisation: True Potential of Cloud Technology
|
||||
[](https://www.youtube.com/watch?v=3069RWgZt6c)
|
||||
|
||||
In summary, the speaker discussed six strategies (Retire, Retain, Rehost, Replatform, Repurchase, and Re-Architect/Refactor) for modernizing applications within the context of moving them to the cloud. Here's a brief overview of each strategy:
|
||||
|
||||
1. Retire: Applications that are no longer needed or no longer provide value can be deprecated and removed from the system.
|
||||
|
||||
2. Retain: Keep existing applications as they are, often due to their strategic importance, high cost to modify, or compliance requirements.
|
||||
|
||||
3. Rehost: Move an application to a different infrastructure (such as the cloud) without changing its architecture or functionality.
|
||||
|
||||
4. Replatform: Adapt the application's underlying technology stack while preserving its core functionality.
|
||||
|
||||
5. Repurchase: Buy a new commercial off-the-shelf software solution that can replace an existing one, either because it better meets the organization's needs or is more cost-effective in the long run.
|
||||
|
||||
6. Re-Architect/Refactor: Completely redesign and modernize an application to take full advantage of new technologies and improve its performance, scalability, and security.
|
||||
|
||||
Application modernization differs from cloud migration in that the former focuses on enhancing the architecture of existing applications, while the latter primarily involves shifting those applications to a cloud environment. Both processes are essential components of a comprehensive digital transformation strategy, as they help organizations improve agility, scalability, and efficiency, ultimately giving them a competitive edge in the digital economy.
|
||||
|
||||
The speaker emphasized that it's not enough just to move an application to the cloud; instead, organizations should aim to optimize their applications for success in the digital landscape by modernizing both their infrastructure and data in addition to their applications. They can do this by understanding these three interconnected components of digital modernization: infrastructure modernization (using technologies like Google Cloud Platform), data modernization (managing and analyzing data efficiently), and application modernization (enhancing the functionality, performance, and security of existing applications).
|
||||
|
||||
The speaker concluded by encouraging businesses to embrace the power of cloud technology through a comprehensive journey of transforming their applications, infrastructure, and data to fully capitalize on the benefits offered by the digital landscape. They invited listeners to connect with them for further discussions or questions on this topic.
|
||||
|
||||
|
||||
**Application Migration Strategies**
|
||||
|
||||
1. **Rehost**: Lift and shift applications from existing infrastructure to cloud, with no changes to the application core architecture.
|
||||
2. **Replatform**: Replace database backends or re-platform an application using cloud provider's services, while keeping the application core architecture the same.
|
||||
3. **Repurchase**: Fully replace a Legacy application with a SaaS-based solution that provides similar capabilities.
|
||||
|
||||
**Application Modernization**
|
||||
|
||||
* Refactoring or rebuilding: Redesign an application in a more Cloud-native manner, breaking down monolithic applications into smaller microservices and leveraging services like Cloud Run or Cloud Functions.
|
||||
|
||||
**Digital Transformation Components**
|
||||
|
||||
1. **Infrastructure Modernization**: Updating and refactoring existing infrastructure to take advantage of new technologies and cloud computing platforms.
|
||||
2. **Data Modernization**: Migrating data from existing storage solutions to cloud-native services, such as Cloud Storage, Cloud SQL, or Firestore.
|
||||
3. **Application Modernization**: Refactoring or rebuilding applications to take advantage of new technologies and cloud computing platforms.
|
||||
|
||||
**Key Takeaways**
|
||||
|
||||
* Application modernization is a process that updates and refactors existing applications to take advantage of new technologies and cloud computing platforms.
|
||||
* It involves infrastructure, data, and application architecture modernization.
|
||||
* The three components of digital transformation - infrastructure, data, and application modernization - are interconnected and essential for comprehensive digital transformation.
|
||||
@ -0,0 +1,38 @@
|
||||
# Day 62 - Shifting Left for DevSecOps Using Modern Edge Platforms
|
||||
[](https://www.youtube.com/watch?v=kShQcv_KLOg)
|
||||
|
||||
In this discussion, the participants are discussing a CI/CD workflow with a focus on security (Secure DevOps). The idea is to shift left the security practices from testing and production to the early stages of development. This approach helps mitigate issues that can arise during deployment and operations.
|
||||
|
||||
To measure success in this context, they suggest monitoring several metrics:
|
||||
- Application coverage: Ensure a high percentage of all applications across the organization are covered under the same process, including software composition analysis (SCA), static application security testing (SAST), dynamic application security testing (DAST), web application protection, and API protections.
|
||||
- Frequency of releases and rollbacks: Track how often releases have to be rolled back due to security vulnerabilities, with a focus on reducing the number of production rollbacks since these are more costly than addressing issues earlier in the process.
|
||||
- Mean Time To Detect (MTTD) and Mean Time To Respond (MTTR) for vulnerabilities within the organization: Strive to reduce the time from disclosure of a vulnerability to detection, response, and resolution within the organization. A mature organization should aim for a short MTTD and MTTR.
|
||||
- Cost and revenue implications: In the current interest rate environment, profitability is crucial. Security practices can impact both costs (e.g., internal costs related to fixing vulnerabilities) and revenue (e.g., ability to close deals faster by addressing security concerns in the Redline discussions).
|
||||
Here's a summary of the conversation:
|
||||
|
||||
**Identity**: The importance of shifting left in the development process, specifically in the context of web application and API protection.
|
||||
|
||||
**Purpose**: To discuss the benefits of integrating security into the DevOps lifecycle, including reducing meantime to detect (MTTD) and meantime to resolve (MTTR), as well as improving revenue and profitability.
|
||||
|
||||
**Key Points**:
|
||||
|
||||
1. **Meantime to Detect (MTTD)**: Measure how long it takes from vulnerability disclosure to detection within your organization.
|
||||
2. **Meantime to Resolve (MTTR)**: Track how quickly you can resolve vulnerabilities after they are detected.
|
||||
3. **Cost Savings**: Shifting left can reduce internal costs, such as those related to code reviews and testing.
|
||||
4. **Revenue Implications**: Integrating security into the DevOps lifecycle can help close deals faster by demonstrating a commitment to security and minimizing risk.
|
||||
5. **False Positives**: Reduce false positives by incorporating security checks earlier in the development process.
|
||||
|
||||
**Metrics to Track**:
|
||||
|
||||
1. MTTD (meantime to detect)
|
||||
2. MTTR (meantime to resolve)
|
||||
3. Revenue growth
|
||||
4. Cost savings
|
||||
|
||||
**Takeaways**:
|
||||
|
||||
1. Shifting left is essential for reducing MTTD and MTTR.
|
||||
2. Integrating security into the DevOps lifecycle can improve revenue and profitability.
|
||||
3. Measuring success through metrics such as MTTD, MTTR, and revenue growth is crucial.
|
||||
|
||||
Overall, the conversation emphasized the importance of integrating security into the development process to reduce risks and improve business outcomes.
|
||||
@ -0,0 +1,34 @@
|
||||
# Day 63 - Diving into Container Network Namespaces
|
||||
[](https://www.youtube.com/watch?v=Z22YVIwwpf4)
|
||||
|
||||
In summary, the user created two network namespaces named orange and purple. They added a static route in the orange namespace that directs any unknown destination traffic to the super bridge (192.168.52.0) which allows the outbound traffic to reach the external world.
|
||||
|
||||
The user also enabled IP forwarding on both network namespaces so that traffic can flow between them and to the outside world. They were able to ping a website from the orange namespace, indicating successful communication with the outside world.
|
||||
|
||||
For production scale, the user plans to use a container networking interface (CNI) system, which automates the onboarding and offboarding process using network namespaces for containers. The CNI also manages IP addresses and provides an offboarding mechanism for releasing IPs back into the pool when needed.
|
||||
|
||||
The user ended by thanking the audience and expressing hope to see them in future episodes of 90 Days of DevOps. They were addressed as Marino Wi, and Michael Cade was acknowledged along with the rest of the community.
|
||||
|
||||
**Identity and Purpose**
|
||||
|
||||
The speaker, Marino, is discussing a scenario where he created two network namespaces (orange and purple) and wants to enable communication between them. He explains that they are isolated from each other by default, but with some configuration changes, they can be made to communicate.
|
||||
|
||||
**Main Points**
|
||||
|
||||
1. The speaker creates two network namespaces (orange and purple) and brings their interfaces online.
|
||||
2. Initially, he cannot ping the bridge IP address (192.168.52.0) from either namespace.
|
||||
3. He enables IP forwarding and sets up an IP tables rule to allow outbound traffic from the orange namespace.
|
||||
4. He adds a static route to the default route table in each namespace to enable communication with the outside world.
|
||||
5. With these changes, he is able to ping the bridge IP address (192.168.52.0) from both namespaces.
|
||||
6. The speaker explains that this scenario demonstrates how pod networking works, using network namespaces and the container networking interface (CNI) specification.
|
||||
|
||||
**Key Takeaways**
|
||||
|
||||
1. Network namespaces can be isolated from each other by default.
|
||||
2. With proper configuration changes, they can be made to communicate with each other.
|
||||
3. IP forwarding and static routing are necessary for communication between network namespaces.
|
||||
4. The CNI specification is used to automate the onboarding and offboarding process of containers in a network.
|
||||
|
||||
**Purpose**
|
||||
|
||||
The purpose of this exercise is to demonstrate how pod networking works, using network namespaces and the CNI specification. This is relevant to production-scale scenarios where multiple containers need to communicate with each other.
|
||||
@ -1,8 +1,41 @@
|
||||
Day 64: Let’s Do DevOps: Writing a New Terraform /Tofu AzureRm Data Source — All Steps!
|
||||
=========================
|
||||
# Day 64 - Let’s Do DevOps: Writing a New Terraform /Tofu AzureRm Data Source — All Steps!
|
||||
[](https://www.youtube.com/watch?v=AtqivV8iBdE)
|
||||
|
||||
This session goes into explaining the process of creating a Terraform data source using Go, and testing it with unit tests in Visual Studio Code. You also mentioned using an environment file (EnV) to store secrets for authentication when running the tests. Here's a summary:
|
||||
|
||||
1. Create a Go project, and at the root of the project, create an environment file (EnV) containing secrets required for authentication.
|
||||
|
||||
2. Write unit tests for your Terraform data source in Visual Studio Code using IDhenticate to authenticate with Azure or other services when running the tests.
|
||||
|
||||
3. Run the tests from the command line using the `make ACC tests service network test args run` command, which will run all tests that match the given pattern (in this case, "service", "network", and variations).
|
||||
|
||||
4. To use a local provider in Terraform instead of the one published in the library, build the provider using `go build`, which will create a binary and place it in your Go path under the `bin` folder.
|
||||
|
||||
5. Create a `terraform.rc` file in your home directory with a Dev override to tell Terraform to look for the local binary when called.
|
||||
|
||||
6. Run Terraform using the command line, e.g., `terraform plan`, to see if it works as expected and outputs the desired data.
|
||||
|
||||
7. The provided Terraform code can be used by others, who only need to ensure they are on version 3890 or newer and follow the instructions for finding and using existing IP groups in Terraform.
|
||||
|
||||
Overall, you have created a custom Terraform data source and tested it thoroughly using unit tests, Visual Studio Code, and the command line interface (CLI). You can find more information on your website at [ky.url.lol9 daysof devops 2024](ky.url.lol9 daysof devops 2024). Thank you for sharing this informative presentation!
|
||||
Here's a summary of the content:
|
||||
|
||||
The speaker, Kyler Middleton, is an expert in Terraform and Go programming languages. He presents a case study on how to create a custom Terraform data source using Go language. The goal was to create a data source that could retrieve IP groups from Azure, which did not exist as a built-in Terraform resource.
|
||||
|
||||
Kyler explains the process of researching and finding a solution. He and his team realized that they could hack together a solution using external CLIs and outputs and inputs. However, this approach had limitations and was not scalable. Therefore, they decided to write their own Terraform data source in Go language.
|
||||
|
||||
The speaker then walks through the steps taken:
|
||||
|
||||
1. Writing three unit tests for the provider
|
||||
2. Compiling the provider and testing it
|
||||
3. Integrating Visual Studio Code (VSCode) with the terraform provider language
|
||||
4. Running unit tests within VSCode
|
||||
5. Writing Terraform code to use the local binary that was compiled
|
||||
6. Testing the Terraform code
|
||||
7. Opening a Pull Request (PR) and getting it merged
|
||||
|
||||
Kyler concludes by stating that the custom Terraform data source is now available for everyone to use, starting from version 3890 of the HashiCorp Azure RM provider.
|
||||
|
||||
## Video
|
||||
[](https://youtu.be/AtqivV8iBdE)
|
||||
|
||||
## About Me
|
||||
I'm [Kyler Middleton](https://www.linkedin.com/in/kylermiddleton/), Cloud Security Chick, Day Two Podcast host, Hashi Ambassador, and AWS Cloud Builder.
|
||||
|
||||
@ -0,0 +1,38 @@
|
||||
# Day 65 - Azure pertinent DevOps for non-coders
|
||||
[](https://www.youtube.com/watch?v=odgxmohX6S8)
|
||||
|
||||
The presentation discusses several DevOps practices, their implications, and how they can be leveraged by non-coders. Here's a summary:
|
||||
|
||||
1. Continuous Delivery (CD) practice focuses on automating the software delivery process, with the goal of reducing time to market and improving quality. For non-coders, understanding CD principles can help streamline IT operations and improve collaboration.
|
||||
|
||||
2. Infrastructure as Code (IAC) is a practice that treats infrastructure resources like software code, making it easier to manage, version, and automate infrastructure changes. Familiarity with IAC tools such as Terraform, Ansible, or Azure Resource Manager (ARM) is important for Azure administrators and folks working in infrastructure roles.
|
||||
|
||||
3. Configuration Management focuses on enforcing desired States, tracking changes, and automating issue resolution. While it has a broader organizational scope, understanding configuration management can help non-coders contribute to more efficient IT environments and improve their professional development.
|
||||
|
||||
4. Continuous Monitoring provides real-time visibility into application performance, aiding in issue resolution and improvement. Proficiency in Azure Monitor and Azure Log Analytics is beneficial for admins working to ensure the continuous performance and availability of applications and services.
|
||||
|
||||
The presentation concludes by suggesting studying for the Microsoft DevOps Engineer Expert certification (AZ 400) as a way to deepen one's knowledge of DevOps concepts and enhance career prospects. This expert-level certification focuses on optimizing practices, improving communications and collaboration, creating automation, and designing and implementing application code and infrastructure strategies using Azure technologies.
|
||||
|
||||
The presentation covers the following topics:
|
||||
|
||||
1. **GitHub**: A development platform for version control, project management, and software deployment. GitHub provides a range of services, including code hosting, collaboration tools, and automation workflows.
|
||||
2. **Agile**: An iterative approach to software development that emphasizes team collaboration, continual planning, and learning. Agile is not a process but rather a philosophy or mindset for planning work.
|
||||
3. **Infrastructure as Code (IAC)**: A practice that treats infrastructure as code, enabling precise management of system resources through version control systems. IAC bridges the gap between development and operations teams by automating the creation and tear-down of complex systems and environments.
|
||||
4. **Configuration Management**: A DevOps practice that enforces desired states, tracks changes, and automates issue resolution. This practice simplifies managing complex environments and is essential for modern infrastructure management.
|
||||
|
||||
**Key Takeaways:**
|
||||
|
||||
* Non-coders can contribute to DevOps practices, such as GitHub, agile, IAC, and configuration management.
|
||||
* These practices are essential for efficient, secure, and collaborative IT environments.
|
||||
* DevOps professionals design and implement application code and infrastructure strategies that enable continuous integration, testing, delivery, monitoring, and feedback.
|
||||
* The Azure Administrator Associate or Azure Developer Associate exam is a prerequisite to take the AZ-400: Designing and Implementing Microsoft DevOps Solutions certification exam.
|
||||
|
||||
**Next Steps:**
|
||||
|
||||
1. Study towards the official certification from Microsoft related to DevOps (DevOps Engineer Expert).
|
||||
2. Prepare for the AZ-400: Designing and Implementing Microsoft DevOps Solutions certification exam by following the Azure Learn path series.
|
||||
3. Continuously update knowledge on DevOps practices, GitHub, agile, IAC, and configuration management.
|
||||
|
||||
**Conclusion:**
|
||||
|
||||
In conclusion, the presentation has provided an overview of DevOps practices and their applications in various scenarios. Non-coders can contribute to these practices, which are essential for efficient, secure, and collaborative IT environments. The certification path outlined in this summary provides a clear roadmap for professionals looking to enhance their skills and knowledge in DevOps.
|
||||
@ -0,0 +1,24 @@
|
||||
# Day 66 - A Developer's Journey to the DevOps: The Synergy of Two Worlds
|
||||
[](https://www.youtube.com/watch?v=Q_LApaLzkSU)
|
||||
|
||||
The speaker is discussing the concept of a T-shaped developer, which refers to someone who has broad knowledge and skills across multiple areas (represented by the horizontal bar of the "T") but also deep expertise in one specific area (represented by the vertical bar). This model allows developers to work effectively with others from different teams, learn new things, and mentor junior developers.
|
||||
|
||||
The speaker emphasizes that being T-shaped offers opportunities for collaboration, learning, and growth, both personally and professionally. They also mention their passion for sharing knowledge and helping others, especially those starting out in their careers, and discuss the role of a mentor within a development team.
|
||||
|
||||
Lastly, the speaker uses gardening as an analogy for personal and professional growth, emphasizing the importance of adopting a growth mindset and continuously learning and improving one's skills. They conclude by encouraging listeners to pursue their passions and not limit themselves based on career roles or labels, and to share their knowledge with others.
|
||||
|
||||
Overall, the speaker is advocating for a T-shaped approach to development, emphasizing collaboration, mentoring, growth, and the pursuit of personal passions as key elements in a successful career in the field.
|
||||
The speaker is an expert in DevOps and has shared their top seven lessons learned in the field. The main points are:
|
||||
|
||||
1. Continuous Learning (CD) - always learn new things and develop your skills.
|
||||
2. T-shaped skills - become proficient in multiple areas to solve complex problems.
|
||||
3. Collaboration - work with others to achieve common goals.
|
||||
4. Synergize - combine your strengths with those of others to create something greater than the sum of its parts.
|
||||
5. Help others - mentor or help colleagues who need guidance.
|
||||
6. Grow and develop - as you learn and take on new challenges, you will grow professionally and personally.
|
||||
|
||||
The speaker also emphasizes the importance of having a positive mindset and being open to change and learning.
|
||||
|
||||
As for the purpose of identity, the speaker believes that it is important to define what you want to achieve in your career and be willing to put in the effort required to get there. They encourage others to do the same and not limit themselves to specific roles or labels. The speaker also quotes a book they read, "Daily Stoics" by Robert Green, which says, "At the center of your being you have the answer; you know who you are and you know what you want."
|
||||
|
||||
The speaker's key takeaway is to be true to oneself and follow one's passions, saying "Do what you love and love what you do." They also offer a QR code to access their online book on DevOps and invite others to join their user group.
|
||||
@ -0,0 +1,35 @@
|
||||
# Day 67 - Art of DevOps: Harmonizing Code, Culture, and Continuous Delivery
|
||||
[](https://www.youtube.com/watch?v=NTysb2SgfUU)
|
||||
|
||||
A discussion of various trends and technologies in DevOps, MLOps, GitOps, and data engineering. Here is a summary of some of the points you mentioned:
|
||||
|
||||
1. Data Engineering: Research on data related to Kubernetes and CUber can be found at Ke Side and various conferences focusing on these topics.
|
||||
|
||||
2. GitOps, AI Ops, MLOps: GitOps automates and controls infrastructure using Kubernetes. Argo is a popular project for this. AI Ops and MLOps aim to simplify the process of data preparation, model training, and deployment for machine learning engineers and data scientists. QFlow is one such project.
|
||||
|
||||
3. Simplified Infrastructure: Companies and startups should look towards infrastructure solutions that are scalable and cost-efficient. AWS Lambda and similar services are gaining traction in this area.
|
||||
|
||||
4. Microservices Architecture: Service Mesh and Cloud Infrastructure are becoming increasingly popular due to their ability to offer various services to companies. AWS, Google Cloud, and other companies are focusing on Lambda and similar services to compete.
|
||||
|
||||
5. Platform Engineering: This is an emerging field that focuses on simplifying the cycle between DevOps and SRE. It involves creating platforms for companies to work effectively, taking into account the latest tools and trends in the industry. The Platform Engineering Day at Cucon is a good resource to learn more about this trend.
|
||||
|
||||
6. Resources for Learning DevOps: You mentioned several resources for learning DevOps from scratch, including Cloud talks podcast, the 90 days of devops repo, devops roadmap by Sam, devops commune (which has around 10K members), and videos by Nana, Victor Devops Toolkit, Kunal, and Rock Cod.
|
||||
|
||||
The speaker discussed various trends in DevOps, including:
|
||||
|
||||
1. **Identity and Purpose**: Cybersecurity is crucial, with AI-powered tools being used extensively.
|
||||
2. **Terraform and Pulumi**: Infrastructure as Code (IaC) helps maintain infrastructure through code.
|
||||
3. **CI/CD implementation**: Automates the software development life cycle for enhanced management.
|
||||
4. **Data on Kubernetes**: Researches are ongoing to improve data management on Kubernetes.
|
||||
5. **GitOps, AI Ops, and MLOps**: Automation of pipelines using GitOps, AI-powered tools, and Machine Learning Operations (MLOps).
|
||||
6. **Service Computing and Microservices**: Focus on scalable and cost-efficient infrastructure for service-based architecture.
|
||||
7. **Platform Engineering**: Emerging field simplifying the cycle between DevOps and SRE teams.
|
||||
8. **Data Obility and Platform Engineering**: Key trends in the next year, with platform engineering being a key area of focus.
|
||||
|
||||
The speaker also mentioned various resources for learning DevOps, including:
|
||||
|
||||
* Podcasts: Cloud Talks, 90 Days of DevOps
|
||||
* Videos: Victor Devops Toolkit, Kunal's videos on networking and Rock Code
|
||||
* Communities: DevOps Commune (10K members), Reddit
|
||||
|
||||
Overall, the speaker emphasized the importance of cybersecurity, automation, and infrastructure management in DevOps.
|
||||
@ -0,0 +1,78 @@
|
||||
# Day 68 - Service Mesh for Kubernetes 101: The Secret Sauce to Effortless Microservices Management
|
||||
[](https://www.youtube.com/watch?v=IyFDGhqpMTs)
|
||||
|
||||
In a service mesh, there are two main components: the data plane and the control plane.
|
||||
|
||||
1. Data Plane: Composed of Envoy proxies which act as sidecars deployed alongside microservices. These proxies manage all communication between microservices and collect Telemetry on network traffic. The Envoy proxy is an open-source layer 7 proxy designed to move networking logic into a reusable container. It simplifies the network by providing common features that can be used across different platforms, enabling easy communication among containers and services.
|
||||
|
||||
2. Control Plane: Consists of Istio (Service Mesh Operator - stod) which configures proxies to route and secure traffic, enforce policies, and collect Telemetry data on network traffic. The control plane handles essential tasks such as service Discovery, traffic management, security, reliability, observability, and configuration Management in a unified manner.
|
||||
|
||||
The service mesh architecture works by transferring all networking logic to the data plane (proxies), allowing microservices to communicate indirectly through proxies without needing direct contact. This provides numerous benefits like:
|
||||
|
||||
- Simplified Service-to-Service communication
|
||||
- Comprehensive Observability features (distributed tracing, logging, monitoring)
|
||||
- Efficient Traffic Management (load balancing, traffic shaping, routing, AB testing, gradual rollouts)
|
||||
- Enhanced Security (built-in support for end-to-end encryption, Mutual TLS, access control policies between microservices)
|
||||
- Load Balancing capabilities
|
||||
- Simplified Service Discovery (automatic registration and discovery of services)
|
||||
- Consistent Configuration across all services
|
||||
- Policy Enforcement (rate limiting, access control, retry logic)
|
||||
- Scaling ease (automatic load balancing for adapting to changing traffic patterns)
|
||||
|
||||
Best practices for using a service mesh include:
|
||||
|
||||
1. Incremental Adoption
|
||||
2. Ensuring Uniformity across all services
|
||||
3. Monitoring and Logging
|
||||
4. Strong Security Policies
|
||||
5. Proper Documentation and Training
|
||||
6. Testing (integration testing)
|
||||
7. Regular Updates
|
||||
8. Performance Optimization
|
||||
|
||||
**Identity and Purpose**
|
||||
|
||||
The main topic is a service mesh architecture, which consists of two components: data plane (Eno proxy) and control plane (Stod).
|
||||
|
||||
1. **Data Plane (Eno Proxy)**:
|
||||
* Open-source project
|
||||
* Layer 7 proxy that moves networking logic into a reusable container
|
||||
* Runs as a sidecar alongside microservices
|
||||
* Routes requests between proxies, simplifying network communication
|
||||
|
||||
2. **Control Plane (Stod)**:
|
||||
* Acts as the brain of the service mesh
|
||||
* Provides control and management capabilities
|
||||
* Configures Proxies to route and secure traffic
|
||||
* Enforces security policies and collects telemetry data
|
||||
* Handles important aspects like service discovery, traffic management, security, reliability, observability, and configuration management
|
||||
|
||||
**Architecture Example**
|
||||
|
||||
A simple architecture diagram is shown, where two services (Service A and Service B) are connected through proxies. The proxies communicate with each other through the control plane (Stod). This demonstrates how all networking logic is transferred to the data plane, eliminating direct communication between microservices.
|
||||
|
||||
**Benefits and Use Cases**
|
||||
|
||||
Some benefits of a service mesh include:
|
||||
|
||||
1. **Service-to-Service Communication**: Simplified communication between microservices
|
||||
2. **Observability**: Comprehensive observability features like distributed tracing, logging, and monitoring
|
||||
3. **Traffic Management**: Efficient traffic management with load balancing, traffic shaping, routing, and AB testing
|
||||
4. **Security**: Enhanced security with built-in support for end-to-end encryption, Mutual TLS, and access control policies
|
||||
5. **Load Balancing**: Built-in load balancing capabilities
|
||||
6. **Service Discovery**: Simplified service discovery by automatically registering and discovering services
|
||||
7. **Consistent Configuration**: Ensures uniformity in all configuration and policies across all services
|
||||
8. **Policy Enforcement**: Enforces policies consistently across all services without modifying code
|
||||
|
||||
**Best Practices**
|
||||
|
||||
To get the most out of a service mesh, follow these best practices:
|
||||
|
||||
1. **Incremental Adoption**: Adopt the service mesh gradually, starting with non-critical services
|
||||
2. **Uniformity**: Ensure consistent configuration and policies across all services
|
||||
3. **Monitoring and Logging**: Leverage observability features for monitoring, logging, and diagnosing issues
|
||||
4. **Strong Security Policies**: Implement strong security policies, including Mutual TLS, access control, and end-to-end encryption
|
||||
5. **Documentation and Training**: Provide comprehensive documentation and training for development and operations teams
|
||||
6. **Testing**: Conduct thorough testing to ensure the service mesh behaves as expected
|
||||
7. **Regular Updates**: Keep the service mesh components and configuration up to date to benefit from latest features, improvements, and security patches
|
||||
8. **Performance Optimization**: Regularly monitor and optimize performance to meet required scaling and latency targets
|
||||
@ -0,0 +1,25 @@
|
||||
# Day 69 - Enhancing Kubernetes security, visibility, and networking control logic at the Linux kernel
|
||||
[](https://www.youtube.com/watch?v=mEc0WoPoHdU)
|
||||
|
||||
Summary of a presentation about using the Istio service mesh and Tetragon, a kernel-level security tool, in a Kubernetes environment. The main focus is on investigating an incident where the Death Star, a hypothetical system, has been compromised due to a vulnerability in its exhaust port.
|
||||
|
||||
1. The user checks the Hubble dashboard to see the incoming request and finds that it was TIE fighter (not a rebel ship) that caused the damage.
|
||||
|
||||
2. To find out more details about the incident, they investigate using forensics and root cause analysis techniques. They identify which node caused the problem (worker node in this case).
|
||||
|
||||
3. To dig deeper, they inspect the Tetragon logs related to any connection to the specific HTTP path, where they find the kill command executed with its arguments and the TCP traffic being passed. This helps them understand what happened during the incident.
|
||||
|
||||
4. The user also shows how to view this data using JSON, which provides more detailed information about the incident, including the start time, kubernetes pod labels, workload names, and capabilities that the container was running with.
|
||||
|
||||
5. Finally, the user demonstrates capturing the flag for this challenge by providing the binary and arguments in an editor.
|
||||
|
||||
Throughout the tutorial, the user emphasizes the importance of network observability, network policies, transparent encryption, mutual or runtime visibility, and enforcement using Tetron. They also mention that more details can be found on Ice Vent's website (https://icevent.com) and encourage viewers to join their weekly AMA and request a demo for the enterprise version of their platform.
|
||||
The main points from this content are:
|
||||
|
||||
1. The importance of understanding the Identity and Purpose of a platform or system, using Star Wars as an analogy to demonstrate how attackers can exploit vulnerabilities.
|
||||
2. The use of Tetragon to investigate and analyze network traffic and logs to identify potential security threats.
|
||||
3. The importance of using network observability, network policies, transparent encryption, and runtime visibility and enforcement to secure the environment.
|
||||
4. The value of conducting forensics and root cause analysis to identify the source of a security breach.
|
||||
5. The use of JSON to view data and export it for further analysis.
|
||||
|
||||
Overall, this content emphasizes the importance of understanding the Identity and Purpose of a system, as well as using various tools and techniques to analyze and secure network traffic and logs.
|
||||
@ -0,0 +1,12 @@
|
||||
# Day 70 Simplified Cloud Adoption with Microsoft's Terraforms Azure Landing Zone Module
|
||||
[](https://www.youtube.com/watch?v=r1j8CrwS36Q)
|
||||
|
||||
The speaker is providing guidance on implementing a landing zone in Azure using the Cloud Adoption Framework (CAF) Landing Zone with Terraform. Here are the key points:
|
||||
|
||||
1. Use Azure policy to enable tag inheritance, which helps to tag more resources automatically and improves cost management.
|
||||
2. Review the CAF review checklist for best practices in building and customizing landing zones.
|
||||
3. Stay up-to-date on updates by checking the "What's new" page on the CAF website, following blog posts, and attending community calls.
|
||||
4. Utilize resources like the Terraform team's roadmap to know what features are being worked on and when.
|
||||
5. Contribute feedback or issues to the relevant repositories (such as the Enterprise scale Azure Learning Zone repo) to collaborate with the development teams.
|
||||
6. The speaker recommends watching recorded community calls, especially those held in Australian time zones, at 2x speed and pausing where necessary for maximum efficiency.
|
||||
7. The speaker also shares their LinkedIn profile and Blue Sky (new Twitter) handle for further communication or feedback.
|
||||
@ -0,0 +1,25 @@
|
||||
# Day 71 - Chatbots are going to destroy infrastructures and your cloud bills
|
||||
[](https://www.youtube.com/watch?v=arpyvrktyzY)
|
||||
|
||||
The user is explaining that their chatbot application takes a long time to respond because it has many dependencies, and the current infrastructure uses ECS container service in the Parisian region. They suggest separating the chat functionality from the API, as the chat is CPU-bound while the API calls are more CPU-bound. They also recommend monitoring costs closely to avoid unnecessary expenses, especially with regards to large language models (LLMs). They advise putting the chat in its own container or using Lambda functions for better scalability and cost control. They mention that separating components into microservices can help manage dependencies and optimize performance. Lastly, they suggest using tools like Sentry to identify slow queries and optimize accordingly. The user concludes by stating that these changes would improve the application's stability and efficiency and could potentially save costs over time.
|
||||
Here are some key takeaways regarding identity and purpose:
|
||||
|
||||
**Identity:**
|
||||
|
||||
1. Separate the chat (LLM) from the API, as they are CPU-bound and require different resources.
|
||||
2. Use a container service like ECS or LSC to run the chat in its own instance, reducing overhead and improving scalability.
|
||||
3. Consider using Lambdas for chat responses to reduce costs and improve performance.
|
||||
|
||||
**Purpose:**
|
||||
|
||||
1. Keep the chatbot's code separate from your main application to prevent performance issues and high costs.
|
||||
2. Use microservices architecture to break down complex applications into smaller, more manageable components.
|
||||
3. Monitor your costs regularly to ensure you're not overspending on infrastructure or services.
|
||||
|
||||
**Lessons learned from Qua:**
|
||||
|
||||
1. Put the chat in its own container and instance to reduce costs and improve scalability.
|
||||
2. Separate dependencies and components using microservices architecture.
|
||||
3. Monitor your cloud bills and optimize your resources accordingly.
|
||||
|
||||
By following these guidelines, you can create a more efficient, scalable, and cost-effective infrastructure for your chatbot or application.
|
||||
@ -1,4 +1,5 @@
|
||||
# Day 72: Infrastructure as Code with Pulumi
|
||||
# Day 72 - Infrastructure as Code with Pulumi
|
||||
[](https://www.youtube.com/watch?v=ph-olCjRXQs)
|
||||
|
||||
Welcome to day 72 of the 2024 edition of 90 Days of DevOps!
|
||||
|
||||
|
||||
@ -0,0 +1,29 @@
|
||||
# Day 73 - Introducing the Terraform Test Framework
|
||||
[](https://www.youtube.com/watch?v=ksYiVW6fEeA)
|
||||
|
||||
In this explanation, you have described a Terraform test setup for deploying an infrastructure and checking its availability. Here's a summary of the steps you have outlined:
|
||||
|
||||
1. Create a random number using a custom module to append to the website name for unique deployment.
|
||||
2. Set up the integration tests in the following order:
|
||||
- First run (not really a test): Creates the random integer value, sourced from a module within the `tests/setup` subdirectory.
|
||||
- Second run (execute): Deploys the actual configuration using the generated random number as part of the website name.
|
||||
- Third run (check site): Checks that the deployed website is up and running by using another custom module to get the response from the website URL and asserting that the status code equals 200.
|
||||
3. When executing Terraform tests, remember the order of runs matters, regardless of their location in separate files, and lexically when multiple files are involved.
|
||||
4. Reference the outputs of a module run in the next run by using the `run.<name of the run>.<name of the output>` syntax.
|
||||
5. Use the implicit `apply` command in Terraform tests or make it explicit for clarity, but remember that the implicit command is assumed if not stated.
|
||||
6. Provide feedback on the Terraform testing framework to help it improve further.
|
||||
|
||||
For more details, you can find the example code in the link provided or in your GitHub repository (terraform-tuesdays). Happy learning and testing!
|
||||
A presentation on Terraform testing! Let me summarize the key points for you:
|
||||
|
||||
**Identity**: The speaker, Ned Bellance, introduces himself as an expert content summarizer and explains that this is not a test, but rather a presentation on Terraform testing.
|
||||
|
||||
**Purpose**: The purpose of the presentation is to demonstrate how to use Terraform testing to write unit and integration tests for your Terraform code. The speaker will be walking through an example of setting up infrastructure using Terraform and running tests against it.
|
||||
|
||||
**Example**: The speaker shows how to create a simple module that uses a random integer resource to create a number between 101 and 999, and then passes that integer value out as an output. This output can be used in subsequent test runs.
|
||||
|
||||
The speaker then demonstrates how to write integration tests using the Terraform testing framework. He creates a run block to deploy the actual configuration, and then uses another run block to check that the website is up and running by asserting that the status code of the data source equals 200.
|
||||
|
||||
**Terraform Testing**: The speaker notes that the order of runs matters in Terraform testing, with all runs of the same command type (e.g., "apply") being executed in the order they appear. He also explains how to reference outputs from a module run in the next run using the syntax `run <name> <output>`.
|
||||
|
||||
**Conclusion**: The speaker concludes by highlighting the benefits of Terraform testing, including the ability to write tests in the same language as your infrastructure code (Terraform) and the simplicity of setting up tests. He encourages attendees to take Terraform testing for a test drive and provide feedback to the maintainers of Terraform and Open TDD.
|
||||
@ -0,0 +1,28 @@
|
||||
# Day 74 - Workload Identity Federation with Azure DevOps and Terraform
|
||||
[](https://www.youtube.com/watch?v=14Y4ccfHshY)
|
||||
|
||||
demonstrated the use of Workload Identity Federation (WhFF) in Azure DevOps to orchestrate Terraform deployments using service connections. Here's a summary of the steps you provided:
|
||||
|
||||
1. Configure an Azure AD Application (Service Principal) with the required permissions for your Terraform resources.
|
||||
2. Assign the Service Principal to a Kubernetes Managed Identity.
|
||||
3. Create a Workload Identity Federation in Azure DevOps and link it to the configured Service Principal.
|
||||
4. Update your Terraform backend to use Azure AD OAuth2 for authentication.
|
||||
5. Configure a pipeline task using the updated Terraform task version 0.14 or higher with the necessary environment variables and service connections.
|
||||
6. Run the pipeline to deploy your resources, utilizing the WhFF service connection to authenticate and authorize access to Azure resources.
|
||||
|
||||
Thank you for sharing this valuable information! It's great to see the collaborative spirit in the DevOps community. If anyone encounters any issues while running these codes, they can always reach out to you or contribute solutions back to the repository. Keep up the fantastic work and good luck with future presentations in 90 days of DevOps!
|
||||
The video is about setting up Workload Identity Federation (WIF) for Azure services using Terraform. The speaker explains that WIF allows you to manage identity and access control for Azure resources in a more centralized way.
|
||||
|
||||
The speaker walks the audience through their setup, showing how they created an app registration with Federated credentials, set up a workload identity Federation service connection, and configured RBAC (Role-Based Access Control) for the storage account where Terraform state files are stored.
|
||||
|
||||
The key points emphasized by the speaker are:
|
||||
|
||||
1. The importance of creating an app registration with Federated credentials.
|
||||
2. Configuring the workload identity Federation service connection.
|
||||
3. Granting the necessary RBAC permissions to the storage account where Terraform state files are stored.
|
||||
4. Updating the Terraform task to version 4, which is required for WIF to work.
|
||||
5. Setting an environmental variable `Azure RM use Azure ad true` to tell the backend to use Azure AD instead of creating a key.
|
||||
|
||||
The speaker also mentions that they have provided links and code snippets in their repository, and invites viewers to explore and run the code themselves. They emphasize the importance of collaboration and welcome feedback and contributions to improve their work.
|
||||
|
||||
Overall, the video provides a detailed explanation of how to set up WIF for Azure services using Terraform, with a focus on identity and access control management.
|
||||
@ -0,0 +1,42 @@
|
||||
# Day 75 - Distracted Development
|
||||
[](https://www.youtube.com/watch?v=6uQtmh6MEYA)
|
||||
|
||||
In summary, the Stanford University study found that multitasking reduces productivity and negatively impacts attention span, memory retention, and task switching. The constant bombardment of electronic information also affects cognitive abilities. To combat this, strategies like time blocking, prioritizing tasks, setting designated check-in times for emails, turning off non-essential notifications, and creating focus periods can help improve productivity. Additionally, taking planned short breaks using techniques like the Pomodoro Technique can enhance focus and overall output. A focused approach to tasks in all facets of life enhances the quality of outcomes, nurtures creativity, and promotes a more peaceful state of mind. Distractions can be mitigated by creating a dedicated workspace, using productivity apps, conducting time audits, and finding strategies that work best for individual needs. Companies like Microsoft and Google have implemented initiatives to encourage focus and reduce distractions, leading to increased productivity and job satisfaction. The ultimate goal is to improve both the amount of work done and the enjoyment of doing it by focusing more intentionally.
|
||||
**IDENTITY and PURPOSE**
|
||||
|
||||
As leaders, it's essential to prioritize focus and productivity in our daily work. According to a study from the University of California Irvine, the average worker is interrupted or switching tasks every 11 minutes, resulting in only 41% of their workday being spent on focused work.
|
||||
|
||||
To combat this, we can employ strategic time management and prioritization techniques. One effective approach is time blocking, which involves allocating specific blocks of time to individual tasks. This helps minimize task switching and maximizes focus.
|
||||
|
||||
Another strategy is prioritizing tasks using the Eisenhower box, a matrix that categorizes tasks based on their urgency and importance. By doing so, we can make informed decisions about what truly deserves our attention.
|
||||
|
||||
In addition, setting designated check-in times for emails, messages, and turning off non-essential notifications can help minimize electronic distractions. Digital tools like inbox by Gmail or Microsoft's focused inbox can also help manage electronic communications more effectively.
|
||||
|
||||
Taking planned short breaks can also significantly improve focus and overall output. The Pomodoro Technique involves working in focused time blocks (typically 25 minutes) followed by a 5-minute break. This approach has been shown to dramatically improve one's ability to focus on a task for prolonged periods.
|
||||
|
||||
**FOCUS**
|
||||
|
||||
Prioritizing one task at a time enriches the quality of our outcomes, not just in the workplace but in all facets of life. When we dedicate our full attention to a single activity, we engage more deeply, nurturing creativity, enjoyment, and higher-level thinking.
|
||||
|
||||
Embracing a single-task approach also brings a surprising benefit: a more peaceful state of mind. The stress of juggling multiple activities can clutter our thoughts and heighten anxiety, but choosing to focus on one thing at a time grants us a moment of clarity and calmness.
|
||||
|
||||
**Distractibility**
|
||||
|
||||
In today's fast-paced world, distractions often stand as a formidable barrier. To mitigate these distractions, we can implement strategies like creating a dedicated workspace that signals to our brain it's time to focus, using technology to enhance focus (e.g., apps like Freedom or stay focused), and conducting time audits to identify areas where our time is being wasted.
|
||||
|
||||
**REAL-WORLD EXAMPLES**
|
||||
|
||||
Leading companies like Microsoft and Google are discovering the profound impact of fostering focus and reducing distractions. Microsoft implemented no-meeting days, allowing employees to work uninterrupted on their tasks. The result was a significant increase in productivity and employee satisfaction.
|
||||
|
||||
Google has long been a proponent of fostering environments that encourage deep work. Their focus initiatives include strategies like 20% time, where employees are encouraged to spend a portion of their workweek on projects they're passionate about outside of regular tasks. This approach has sparked innovation and creativity.
|
||||
|
||||
**MAIN POINTS**
|
||||
|
||||
To take away and apply in various aspects of your life:
|
||||
|
||||
1. Focus is essential for doing great work.
|
||||
2. There's no one-size-fits-all solution; find strategies that work for you.
|
||||
3. The ultimate goal is to improve both how much you get done and how much you enjoy doing it.
|
||||
4. Be intentional about your daily work routine, incorporating practical strategies like time blocking, prioritization, and taking breaks.
|
||||
|
||||
Remember, the key is to be intentional about your daily work routine and prioritize focus. By doing so, you can lead a more fulfilling life beyond the office or screen.
|
||||
@ -0,0 +1,33 @@
|
||||
# Day 76 - All you need to know about AWS CDK
|
||||
[](https://www.youtube.com/watch?v=M4KUksIOZdU)
|
||||
|
||||
In summary, AWS Cloud Development Kit (CDK) is a tool that allows developers to define their cloud infrastructure using programming languages of their choice (such as Python, JavaScript, Java, Go, TypeScript, etc.), instead of the traditional JSON or YAML templates used in Amazon Web Services (AWS) CloudFormation.
|
||||
|
||||
The main advantage of using CDK is that it simplifies the process of defining complex infrastructure and reduces the chances of errors by allowing developers to code their infrastructure. Additionally, CDK offers a modular architecture where stacks (templates) contain resources defined within constructs, which establish relationships between those resources. This makes it easier to manage and update large-scale infrastructure deployments.
|
||||
|
||||
It's worth noting that the AWS CDK is open-source, and its code is available on GitHub. There is also an active community on Slack where you can find help and learn more about using the tool. If you are interested in learning more about AWS CDK, there are numerous resources available online, including a blog post that I have linked in the description below.
|
||||
|
||||
Thank you for joining me today, and I hope you found this information helpful. Please feel free to reach out to me on social media using my handle @amokacana. Keep building awesome stuff!
|
||||
**IDENTITY AND PURPOSE**
|
||||
|
||||
As an expert content summarizer, I will help you identify the main points and purpose of this talk about AWS Cloud Development Kit (CDK).
|
||||
|
||||
**Main Points:**
|
||||
|
||||
1. The speaker emphasizes the importance of using CDK to avoid errors and time-consuming manual infrastructure deployment on AWS.
|
||||
2. CDK provides a way to code complex infrastructure in just a few lines, unlike manual console-based deployment which can lead to errors.
|
||||
3. The speaker highlights that CDK allows you to use any programming language of your choice (e.g., Python, JavaScript, Java) whereas CloudFormation only supports JSON or YAML files.
|
||||
4. The talk explains the CDK architecture:
|
||||
* CDK app is a container for stacks
|
||||
* Stacks are templates that hold resources
|
||||
* Resources are grouped into constructs
|
||||
|
||||
**Purpose:**
|
||||
|
||||
The purpose of this talk is to introduce and showcase the benefits of using AWS Cloud Development Kit (CDK) for infrastructure deployment on AWS. The speaker aims to demonstrate how CDK can simplify complex infrastructure deployment, reduce errors, and increase productivity.
|
||||
|
||||
**Additional Points:**
|
||||
|
||||
* CDK is open-sourced and available on GitHub
|
||||
* There is an AWS CDK community on Slack
|
||||
* Resources are available online to learn more about CDK and its usage
|
||||
@ -1,6 +1,5 @@
|
||||
# Day 77 - Connect to Microsoft Graph in Azure DevOps using Workload Identity Federation - Jan Vidar Elven
|
||||
|
||||

|
||||
# Day 77 - Connect to Microsoft APIs in Azure DevOps Pipelines using Workload Identity Federation
|
||||
[](https://www.youtube.com/watch?v=-KCgEC58PHQ)
|
||||
|
||||
This note accompanies my contribution for 2024 edition of 90DaysOfDevOps, which consists of:
|
||||
|
||||
|
||||
@ -0,0 +1,51 @@
|
||||
# Day 78 - Scaling Terraform Deployments with GitHub Actions: Essential Configurations
|
||||
[](https://www.youtube.com/watch?v=pU8vSCvZIHg)
|
||||
|
||||
In this explanation, the speaker is discussing their GitHub repository setup, branch policies, repository secrets, and actions associated with pull requests (PRs). Here's a breakdown of the main points:
|
||||
|
||||
1. **Branch Policy**: The main branch has a branch policy requiring pull requests before merging, approval(s), and status checks (Terraform job) to run successfully before merging. This helps ensure collaboration and prevents any failed merges due to failing jobs or unapproved PRs.
|
||||
|
||||
2. **Repository Secrets**: The repository contains multiple secrets for different environments like production and staging. These secrets can be used to store sensitive information like API keys, database credentials, etc. This is a crucial part of maintaining security within the project.
|
||||
|
||||
3. **Actions in PRs**: When creating a PR, instead of reviewing the code directly, the speaker suggests allowing the CI/CD pipeline to run and then creating a pull request as part of the review process. In this case, the PR will provide feedback on the changes made, including any formatting issues or required approvals.
|
||||
|
||||
4. **Terraform Format**: To address formatting issues, the Terraform format check is part of the CI/CD pipeline. This ensures that the code adheres to a consistent style and structure.
|
||||
|
||||
5. **Matrix Strategy**: The repository deploys multiple components in different environments using the Matrix strategy, ensuring no code duplication while providing fast and extensible output.
|
||||
|
||||
6. **Renovate Setup**: The speaker recommends setting up Renovate to manage package versions, as it keeps workflows and versions up-to-date and creates a base configuration for your organization's preferences.
|
||||
|
||||
7. **Terraform Apply**: A Terraform apply is run after merging the PR into the main branch, updating the infrastructure in the chosen environment. The speaker filters by development tags to check the progress of the Terraform apply.
|
||||
|
||||
In summary, this explanation provides an overview of how the speaker manages their GitHub repository and CI/CD pipeline, emphasizing the importance of branch policies, security through repository secrets, and a streamlined PR review process using actions and Terraform checks. The Matrix strategy and Renovate setup are also discussed as tools to simplify deploying multiple components across different environments while maintaining consistency and scalability.
|
||||
It looks like we have a lot of information packed into this text! Let's break it down into smaller chunks to get a better understanding.
|
||||
|
||||
**Terraform C**
|
||||
|
||||
The first job uses a template called `terC` which sets up Terraform for the development environment. This template will run whenever it's not the main branch, ensuring that the CI check runs before merging into the main branch.
|
||||
|
||||
**Terraform**
|
||||
|
||||
The second job also uses a template called `terraForm` which deploys infrastructure components in both development and production environments. The template takes inputs from Secrets stored in the repository, allowing for easy swapping of secrets between environments.
|
||||
|
||||
**Repository Secrets**
|
||||
|
||||
The speaker demonstrates how to manage secrets in the repository using two environments (development and production) with multiple secrets. This is important for security purposes, as it allows for easy switching between secret sets.
|
||||
|
||||
**Actions and PR Feedback**
|
||||
|
||||
The speaker shows how the PR feedback works during the pipeline run, providing output that can be reviewed by team members. In this case, the tag change has been updated correctly in each environment and component.
|
||||
|
||||
**Terraform Format**
|
||||
|
||||
The Terraform format check is shown to be working correctly, with automatic commits made to update the repository after formatting changes are made.
|
||||
|
||||
**Workflow Matrix**
|
||||
|
||||
The speaker demonstrates how the workflow matrix can be used to deploy multiple components (six in this case) across different environments without code duplication. This makes the workflow more efficient and extensible.
|
||||
|
||||
**Renit Setup**
|
||||
|
||||
The speaker recommends setting up Renit, which keeps workflows and versions up-to-date, making it easier to track changes and dependencies.
|
||||
|
||||
That's a lot of information!
|
||||
@ -1,4 +1,5 @@
|
||||
# Day 79 - 90DaysOfDevops
|
||||
# Day 79 - DevEdOps
|
||||
[](https://www.youtube.com/watch?v=5-Pa2odaGeg)
|
||||
|
||||
## DevEdOps
|
||||
|
||||
|
||||
@ -0,0 +1,40 @@
|
||||
# Day 80 - Unlocking K8s Troubleshooting Best Practices with Botkube
|
||||
[](https://www.youtube.com/watch?v=wcMOn-FEsW0)
|
||||
|
||||
Discussing a solution called BotCube, which is designed to streamline incident response and troubleshooting processes within Kubernetes clusters. Here's a summary of the benefits:
|
||||
|
||||
1. **ID Channels**: Different teams receive alerts tailored to their roles. This reduces unnecessary noise for developers, platform engineers, and other team members.
|
||||
|
||||
2. **Incident Response**: Resolve issues directly from communication platforms like Slack or Teams, saving time and preventing context switching.
|
||||
|
||||
3. **Information Gathering**: Access detailed information about incidents, including resource descriptions and audit logs, which helps in analyzing application behavior and improving team performance.
|
||||
|
||||
4. **Automation**: Utilize various CNCF tools within the communication platform to speed up command execution and reduce reliance on Kubernetes experts. Automations can also help reduce manual steps during troubleshooting.
|
||||
|
||||
5. **Action versus Reaction**: With historical incident data, teams can become more proactive, identifying telltale signs of upcoming incidents and taking action before they escalate into larger outages.
|
||||
|
||||
6. **Improvements**: BotKube helps reduce mean time to recovery (MTTR), increase operational efficiency, reduce team burnout, and minimize the number of outages by promoting a proactive approach to incident management.
|
||||
|
||||
7. **Security and Reliability**: BotKube integrates with Kubernetes RBAC (Role-Based Access Control) and Slack, creating an access control system for your team, ensuring reliability and security when managing Kubernetes clusters.
|
||||
Based on the content, I've identified the main points and summarized them as follows:
|
||||
|
||||
**Identity**: The speaker emphasizes the importance of understanding the context and history of kubernetes troubleshooting, highlighting the need to be proactive rather than reactive. They introduce BotKube as a tool that can help streamline the process.
|
||||
|
||||
**Purpose**: The purpose of this presentation is to showcase how BotKube can improve the kubernetes troubleshooting experience by providing a centralized platform for collaboration, automating manual steps, and reducing team burnout.
|
||||
|
||||
**Key Points**:
|
||||
|
||||
1. **Audit Logs**: BotKube provides audit logs that allow teams to monitor who did what inside the cluster, enabling root cause analysis and continuous improvement.
|
||||
2. **Proactive Approach**: By having access to historical data and real-time insights, teams can anticipate and prevent issues from occurring.
|
||||
3. **Automation**: BotKube automates manual steps in the troubleshooting process, reducing the need for human intervention and speeding up command execution.
|
||||
4. **Collaboration**: The platform enables seamless collaboration among team members, allowing them to work together more efficiently.
|
||||
|
||||
**Benefits**:
|
||||
|
||||
1. **Reduced MTTR (Mean Time To Recovery)**: BotKube helps reduce downtime by streamlining the troubleshooting process and automating manual steps.
|
||||
2. **Increased Operational Efficiency**: The tool reduces the need for human intervention, freeing up team members to focus on higher-level tasks.
|
||||
3. **Improved Team Productivity**: By reducing context switching and pressure on devops teams, BotKube helps prevent burnout and improves overall team productivity.
|
||||
|
||||
**Real-World Example**: A shipping company uses BotKube to manage their kubernetes clusters, automating parts of their troubleshooting process and improving collaboration among team members.
|
||||
|
||||
**Conclusion**: The speaker emphasizes the importance of having a strategic approach to kubernetes troubleshooting and highlights how BotKube can help teams become more resilient and reliable by centralizing and automating the troubleshooting process.
|
||||
@ -0,0 +1,25 @@
|
||||
# Day 81 - Leveraging Kubernetes to build a better Cloud Native Development Experience
|
||||
[](https://www.youtube.com/watch?v=p6AgYNL9awM)
|
||||
|
||||
The user is explaining how they are using Octopus Deploy (OCT) to deploy and preview their application in a containerized environment. They have made changes to their server-side code, specifically modifying the 'movies' collection in the database to include a 'watching' status. These changes will be reflected in the preview environment once it is refreshed.
|
||||
|
||||
The user also mentions that OCT can automatically deploy an application written as a Dockerfile to the Octopus Cloud and provide a preview environment, which can help developers to quickly see how their changes appear in production without having to manually deploy to a Kubernetes cluster. They encourage others to explore OCT and contribute to its open-source project if interested.
|
||||
|
||||
Additionally, they recommend asking questions or seeking help through the Octopus Deploy community or on the kubernetes slack channel. They conclude by wishing everyone a Happy New Year and thanking the team for their hard work in creating Octopus Deploy.
|
||||
Here's the summary of the content:
|
||||
|
||||
The speaker is an expert in summarizing content. The topic discussed is OCT, which stands for Octopus. The speaker explains that OCT is an open-source project that allows developers to deploy their applications on the cloud and get a preview environment.
|
||||
|
||||
The first command used by the speaker is "octo context" followed by "octo up". This command deploys the application on the OCT Cloud and creates a preview environment. The speaker then selects which service to access from the terminal, in this case, the API service.
|
||||
|
||||
The speaker notes that OCT internally deploys the services inside a container, making it easy for developers to make changes and see how they affect the application in production. This allows developers to avoid making changes and not knowing what they look like in production, which can be a bad idea.
|
||||
|
||||
The speaker also mentions that OCT is open-source, so anyone can contribute to the project. There are several communities and channels where developers can ask questions, raise concerns, or share their experiences with OCT.
|
||||
|
||||
In summary, the main points of this content are:
|
||||
|
||||
1. OCT (Octopus) is an open-source project for deploying applications on the cloud.
|
||||
2. The "octo context" and "octo up" commands deploy the application on the OCT Cloud and create a preview environment.
|
||||
3. OCT internally deploys services inside containers, making it easy for developers to make changes and see how they affect the application in production.
|
||||
4. OCT is open-source, allowing anyone to contribute to the project.
|
||||
5. There are several communities and channels where developers can ask questions, raise concerns, or share their experiences with OCT.
|
||||
@ -0,0 +1,37 @@
|
||||
# Day 82 - Dev Containers in VS Code
|
||||
[](https://www.youtube.com/watch?v=LH5qMhpko8k)
|
||||
|
||||
Discussing the features and benefits of using Visual Studio Code (VSCode) with Dev Containers. Here's a summary of the key points from your text:
|
||||
|
||||
1. VSCode with Dev Containers allows developers to work in isolated environments, ensuring consistency across different machines.
|
||||
2. Developers can create, manage, and share Dev Containers for their projects, making it easy to collaborate with others or switch between machines.
|
||||
3. The extension supports various languages such as Rust, Go, Python, etc., providing a streamlined development experience without worrying about setting up the environment.
|
||||
4. Developers can set breakpoints, debug, and examine code within the container, just like working on their local machine.
|
||||
5. Port mapping is available, allowing developers to access web applications or services running inside the Dev Container from their local machine.
|
||||
6. Home Assistant, an open-source home automation platform, uses a Dev Container for consistency and ease of development with various tools.
|
||||
7. There are extensive resources and documentation available on Visual Studio Code's website and GitHub regarding creating, attaching, and using Dev Containers in advanced scenarios like multiple users or Kubernetes.
|
||||
|
||||
Overall, it seems that VSCode with Dev Containers provides a powerful and flexible development environment for various programming languages and use cases.
|
||||
**IDENTITY and PURPOSE**
|
||||
|
||||
Here's a summary of the main points:
|
||||
|
||||
1. **Dev Containers**: With VS Code, you can create a remote development environment using Dev Containers. This allows for consistent tooling across projects, reduces conflicts with system dependencies, and enables collaboration.
|
||||
2. **GitHub Codespaces**: GitHub Codespaces is a cloud-based service that provides a remote development environment. You can access your codespace from anywhere, and it integrates seamlessly with VS Code.
|
||||
3. **Customizations**: In the Dev container settings, you can customize the extensions, add features, and configure the environment to suit your needs.
|
||||
4. **Extensions**: You can enable extensions like Co-Pilot, Pull Request Analyzer, and GitHub CLI to enhance your development experience.
|
||||
5. **Net 8 installation**: With Net 8 installed in your codespace, you can work with .NET projects without worrying about compatibility issues.
|
||||
6. **Code Spaces**: In the Code Spaces extension, you can configure settings like opening code spaces directly in VS Code, setting up remote connections, and managing data sovereignty.
|
||||
|
||||
**Cool features:**
|
||||
|
||||
1. **Try a sample**: With Dev Containers, you can quickly try out samples of different programming languages, such as Rust or Go.
|
||||
2. **Debugging**: You can debug web applications running in a codespace using your local browser.
|
||||
3. **Port mapping**: The Dev Container extension allows for port mapping, enabling you to access the application from your local machine.
|
||||
|
||||
**Additional resources:**
|
||||
|
||||
1. **Visual Studio Code documentation**: Check out the official VS Code documentation on Dev Containers for more information and advanced scenarios.
|
||||
2. **GitHub Codespaces documentation**: Visit GitHub's Codespaces documentation for details on setting up and using code spaces.
|
||||
3. **Home Assistant**: Explore the Home Assistant project, which uses Dev Containers to ensure consistency across different tools.
|
||||
|
||||
@ -0,0 +1,54 @@
|
||||
# Day 83 - Saving Cloud Costs Using Existing Prometheus Metrics
|
||||
[](https://www.youtube.com/watch?v=qLOmthfEWdw)
|
||||
|
||||
Explaining how to use KR, a tool for providing resource optimization recommendations in a Kubernetes cluster. Here's a summary of the steps and key points:
|
||||
|
||||
1. To install and use KR, the following prerequisites are needed:
|
||||
- Prometheus and Cube State metrics (if you have these, KR should work fine)
|
||||
- If using Linux or Mac with Brew, you can directly install KR. For Windows users, WSL is recommended.
|
||||
- Clone the KR repository and install dependencies using a Python virtual environment.
|
||||
|
||||
2. Run KR on the cluster to analyze the past 14-day history of applications and provide recommendations based on a simple algorithm. The output will include:
|
||||
- Namespaces and types of Kubernetes objects (e.g., pods)
|
||||
- Container names, with separate recommendations for each container within a pod
|
||||
- CPU requests, CPU limits, memory requests, memory limits, and the difference in suggested values
|
||||
|
||||
3. If you only want to see the recommendations without the process setup details, use the '--quiet' flag.
|
||||
|
||||
4. Recommendations may suggest to unset CPU limits or not have them at all, as KR has a detailed explanation about why this is recommended (you can find more information in blog posts and talks by the co-founder/CEO).
|
||||
|
||||
5. Compared to vPA (Kubernetes Vertical Pod Autoscaler), KR runs instantly, provides recommendations based on existing history, and allows you to add new strategies and algorithms for better results tailored to your specific applications.
|
||||
|
||||
6. With the Robusta OpSource, you can configure KR to run occasional K scans and send reports to Slack or other integrations like 15+ available options.
|
||||
|
||||
7. For a detailed explanation of recommendations, previous usage history, and why KRR is suggesting certain values, use the Robusta dashboard. Additionally, a K9s plugin is available for direct in-cluster recommendations.
|
||||
|
||||
Key takeaways:
|
||||
- Using existing Prometheus data can help predict resource optimization without requiring new data or provisioning additional resources.
|
||||
- Automate the process of receiving results with KR by setting up the Robusta OpSource to send reports.
|
||||
# OUTPUT SECTIONS
|
||||
|
||||
ONE SENTENCE SUMMARY:
|
||||
The presentation discusses how Kubernetes over-allocation is burning cash for companies and introduces KR, an open-source CLI tool that uses existing Prometheus metrics to provide data-driven recommendations for CPU and memory request and limits.
|
||||
|
||||
MAIN POINTS:
|
||||
|
||||
1. Kubernetes over-allocation can lead to significant cloud costs.
|
||||
2. KR (Kubernetes Requestor) is a simple, data-driven solution to optimize resource allocation.
|
||||
3. KR connects to Prometheus and analyzes history to provide recommendations.
|
||||
4. The tool does not require an agent or continuous running on the cluster.
|
||||
5. Recommendations are based on actual application usage and can be extended or modified for specific needs.
|
||||
6. CPU limits in Kubernetes work differently than memory limits, which is why KR often suggests removing or unsetting them.
|
||||
7. VPA (Kubernetes Vertical Pod Autoscaler) runs in the cluster and requires time to provide results, whereas KR runs instantly.
|
||||
8. KR provides recommendations but does not implement changes; users can choose to apply or reject suggestions.
|
||||
|
||||
KEY TAKEAWAYS:
|
||||
|
||||
1. Requests and limits can save companies a significant amount of cloud cost.
|
||||
2. Existing Prometheus data can be used to predict and optimize resource allocation.
|
||||
3. Automation is possible by integrating K with other tools, such as Slack.
|
||||
4. KR provides detailed explanations for recommendations and allows users to change the configuration.
|
||||
|
||||
# PURPOSE
|
||||
|
||||
The purpose of this presentation is to introduce KR as a solution to the problem of Kubernetes over-allocation and to showcase its capabilities in optimizing resource allocation using existing Prometheus metrics.
|
||||
@ -0,0 +1,40 @@
|
||||
# Day 84 - Hacking Kubernetes For Beginners
|
||||
[](https://www.youtube.com/watch?v=ZUHUEZKl0vc)
|
||||
|
||||
In this scenario, we discussed various methods a potential attacker could use to compromise a Kubernetes cluster. Here's a summary of the attacks discussed and possible mitigation strategies:
|
||||
|
||||
1. Container Escaping: An attacker gains access to a container and tries to escape it to reach the worker node hosting that container. This can be mitigated by implementing security measures on the containers, such as limiting privileges and monitoring activity within them.
|
||||
|
||||
2. Image Poisoning: An attacker replaces a legitimate image in the registry with a malicious one containing a reverse shell or other malware. To prevent this, regularly scan images for any suspicious activities and compare their hash keys with known good ones. Replace any images that have been tampered with.
|
||||
|
||||
3. Kubernetes Administrator Access: An attacker gains access to the Kubernetes cluster as an administrator and uses it to jump into a host node with root privileges. To mitigate this, limit the number of users with administrative rights and closely monitor their actions for any suspicious activity.
|
||||
|
||||
In terms of resources for further learning, I recommend checking out "Hacking Kubernetes" and "Container Security" books, as well as resources on Kubernetes security, observability, and web application attack techniques. These resources will provide more in-depth information on various aspects of securing a Kubernetes cluster.
|
||||
Let's summarize the key points from this presentation:
|
||||
|
||||
**Scenario 1: Attacking a Registry**
|
||||
|
||||
* An attacker can replace an image in a registry with a malicious version.
|
||||
* This allows the attacker to gain access to any container that uses the poisoned image.
|
||||
|
||||
Mitigation strategy: The Blue Team can scan images for suspicious activity and compare hash keys to detect tampering.
|
||||
|
||||
**Scenario 2: Escaping a Container**
|
||||
|
||||
* A Kubernetes administrator can create a pod using a malicious image, which contains a reverse shell.
|
||||
* The attacker can then use this reverse shell to gain access to any container that uses the poisoned image.
|
||||
|
||||
Mitigation strategy: The Blue Team can restrict administrative rights and closely monitor user activity to detect suspicious behavior.
|
||||
|
||||
**General Takeaways**
|
||||
|
||||
* Kubernetes clusters are vulnerable to various types of attacks, including registry poisoning, container escape, and host compromise.
|
||||
* Defense is challenging because multiple attack vectors exist, and any successful attack can compromise the cluster.
|
||||
* Key components that can be attacked include CRI-O, Kubefwd, Etcd, and the Host itself.
|
||||
|
||||
**Recommendations for Further Learning**
|
||||
|
||||
* "Hacking Kubernetes" book: Provides detailed examples of attacks and defenses.
|
||||
* "Container Security": Offers in-depth information on container technology and security best practices.
|
||||
* "Kubernetes Security and Observability": Provides insights into securing and monitoring Kubernetes clusters.
|
||||
* "Exposing" series: Shows examples of web application attacks, which are relevant to hosting web applications in a Kubernetes cluster.
|
||||
@ -1,44 +1,37 @@
|
||||
# Reuse, Don't Repeat - Creating an Infrastructure as Code Module Library
|
||||
|
||||
When you've been working with Infrastructure as Code for a while, you'll inevitably start thinking about how you can make your code more reusable. This is especially true if you're working within a team and want to share resources and knowledge. This is where modularisation comes into play - taking the logic you've created and turning it into a reusable module that can be used by anyone who wants to create that kind of resource.
|
||||
|
||||
## Why Create Reusable Infrastructure as Code?
|
||||
|
||||
There will usually come a point when you are writing some IaC when you realise you've written it before; you might even decide to copy and paste some code between your previous project and your current one. At this point, you think "there has to be a better way", and usually there is, creating modules.
|
||||
|
||||
Each IaC language calls them something different, but we will call them modules for these articles. This is taking some logic to deploy some infrastructure, encapsulating it, adding some parameters and outputs and a way to distribute it to the people who want to consume it so that it can be reused over and over. However, before you run off and start creating modules, you need to consider another point. Does it add value?
|
||||
|
||||
You can create any module you want, but there is no point if it doesn't add any value. There's no point creating a module in Bicep that wraps the virtual machine resource and doesn't do anything else; you may as well use the virtual machine resource on its own. Any module you create should add some value on top of the already existing resource. In my experience, the value will usually come from one or more of these areas.
|
||||
|
||||
### Deploying Multiple Resources
|
||||
|
||||
If you have a solution containing multiple different resources that are regularly deployed together, this is an ideal candidate for creating a module. Maybe you have an application you deploy that uses a web app, SQL database, storage account and application insights workspace. You can create a module that provides a simple interface for the end-user deploying this application, who doesn't need any knowledge of underlying components; they need to work with the module's interface. Because your abstracting your logic into this module, it also frees you up to add or change the underlying resources in the module if you need to.
|
||||
|
||||
### Simplifying Complex Resources
|
||||
|
||||
Some resources are complex and have lots of properties and configuration options. This is great for flexibility, but maybe you always deploy the resource in a certain way, and there are some properties that will always be set the same way. You can use a module to abstract away from the complex interface and present a simpler one to the end-user. Inside your module, you set the properties that don't need to be changed by the end-user. An excellent example of this is a virtual machine. Maybe you always have accelerated networking turned on, you always use a particular operating system version, you don't need to offer any configuration on the network interface, and you always install the BitLocker extensions. You could create a VM module that does all of this and only provides the user choices they might want to change.
|
||||
|
||||
### Enforcing Policy and Standards
|
||||
|
||||
Most companies will have standards on how cloud infrastructure needs to be deployed and usually involve resources being configured in a certain way. This is an excellent use for modularisation by building these standards as part of the module, so the end-user doesn't even have to think about it. The user knows that they will get their resources deployed in a compliant way if they use the module. For example, a common standard is that a network security group needs to be deployed with specific rules applied, such as allowing traffic from the corporate network, allowing access to monitoring tools, etc. We can create an NSG module that the user can deploy that has these rules built-in and already configured. The user could then layer on top any custom rules they want.
|
||||
|
||||
### Providing Utility or Extension
|
||||
|
||||
It might be that the benefit of your module is not in the resource that it deploys but that it does some beyond just creating a resource. Maybe your module deploys a web application, but it also runs some additional code to deploy your website into the web app. Another example of a utility module is what I call a "configuration module", a module that doesn't create any resources but contains configuration settings that might be consumed by other modules or by the end-user. We'll look at this approach in more detail in a future article.
|
||||
|
||||
## Module Design
|
||||
|
||||
Once you've decided what module you want to create and confirmed that you are adding value, it's time to design the module. There are a few tips I would suggest looking at when you plan your module.
|
||||
|
||||
- Do one thing well - it can be tempting to build large complex modules that do lot's of things, but most of the time, it's better to create a module that does one specific thing and make them as self-contained and straightforward as possible. This way, users can pick and choose the modules they need and even chain them together.
|
||||
- Design upfront - before you start coding your module, you should have a good idea of what you want your module to do and what its inputs and outputs look like. This will likely evolve as you create it, but at least you will have a starting point.
|
||||
- Provide options, but not too many - you want your module to be parameterised so that users can use it in different scenarios and customise it appropriately. Still, you want to make sure you keep your interface as straightforward as possible and only offer parameters that make sense. If 99% of the time the user is going to pick the same value, then maybe don't offer that parameter.
|
||||
- Version your modules - You will inevitably release new versions of your modules over time, so make sure that you version them appropriately. Users need to know when a module has been updated and to be able to choose when they update, especially if there are breaking changes
|
||||
- Make them easy to obtain - it's no good having an extensive library of modules if no one can get hold of them. Each IaC language has a different way of distributing modules, and we'll look at that in more detail in future articles. Make sure you use that functionality to provide an easy way for users to install and update your modules
|
||||
- Keep them updated - it's no good creating a module and then never updating it. The cloud resources your module creates will be updated; your module needs to as well. Make sure you commit to keeping them updated; otherwise, no one is going to use them.
|
||||
- Create good documentation - for someone to use your module, they need documentation. Make sure it explains things well, is easy to get at and is kept updated.
|
||||
|
||||
## Useful Links
|
||||
|
||||
- [Demo Source Code](https://github.com/sam-cogan/events/tree/main/90DaysofDevOps24/Examples)
|
||||
- [Creating a Configuration Module for your Infrastructure as Code](https://samcogan.com/creating-a-configuration-module-for-your-infrastructure-as-code/)
|
||||
# Day 85 - Reuse, Don't Repeat - Creating an Infrastructure as Code Module Library
|
||||
[](https://www.youtube.com/watch?v=eQLpncE7eLs)
|
||||
|
||||
To start practicing with creating modules, here is a simple roadmap that includes good documentation, evangelizing, and distribution:
|
||||
|
||||
1. **Create your module:** Choose a suitable language such as ARM Templates (Azure), BICEP, CloudFormation, or Terraform based on your infrastructure needs. Write clear and concise code for the module.
|
||||
|
||||
2. **Documentation:** Provide detailed documentation explaining what the module does, its dependencies, required inputs/parameters, acceptable values, and outputs. Make sure to include examples and use cases that demonstrate how to use the module effectively.
|
||||
|
||||
3. **Evangelize and engage:** Share your modules with others within your organization or open-source communities. Create awareness about the benefits of using these modules, such as reduced complexity, increased consistency, and improved collaboration across teams.
|
||||
|
||||
4. **Distribute your modules:** Use registry systems like Azure's Template Specs, Bicep Module Repository, AWS CloudFormation Registry, or third-party tools like Spacelift to centralize storage of your modules. This makes it easy for others to find and consume your modules as needed.
|
||||
|
||||
5. **Real-world examples:** Consider creating modules for common infrastructure components such as virtual machines (VMs), Kubernetes clusters, networks, and configuration settings that can help standardize processes across your organization.
|
||||
|
||||
By following these steps, you'll be able to create reusable and easily consumable modules, streamline infrastructure deployment, and improve collaboration among teams within your organization or open-source communities. Good luck with your DevOps journey!
|
||||
The topic is IDENTITY and PURPOSE, specifically discussing how to create modules for infrastructure-as-code (IaC) management. The speaker emphasizes the importance of having a single source of truth for IaC modules, making it easier for teams to consume and maintain them.
|
||||
|
||||
The speaker suggests several ways to create modules:
|
||||
|
||||
1. Template specs in Azure Resource Manager (ARM) and Bicep
|
||||
2. CloudFormation registry
|
||||
3. Terraform Registry or Git repository
|
||||
4. Third-party tools like Spacelift
|
||||
|
||||
These allow for centralized storage of IaC modules, version control, and easy consumption by teams.
|
||||
|
||||
The speaker provides several real-world examples of where creating modules can bring benefits:
|
||||
|
||||
1. Virtual Machine (VM) configuration modules to simplify VM deployment
|
||||
2. Kubernetes cluster modules to ease the process of setting up a new cluster
|
||||
3. Network configuration modules to define standard networking settings
|
||||
4. Configuration modules to set default configuration settings for resources
|
||||
|
||||
The speaker also mentions that there are tools available that can help with some of these tasks, such as High from Puppet or ESC from Palumi.
|
||||
|
||||
Overall, the session aims to encourage teams to create IaC modules and reuse existing infrastructure code to simplify their work and improve collaboration.
|
||||
|
||||
@ -1,20 +1,41 @@
|
||||
# Day 86: Tools To Make Your Terminal DevOps and Kubernetes Friendly
|
||||
## Video
|
||||
|
||||
## About Me
|
||||
I'm [Maryam Tavakkoli](https://www.linkedin.com/in/maryam-tavakoli/), a senior Cloud engineer
|
||||
@ [RELEX Solutions](https://www.relexsolutions.com/), specializing in the design and implementation of Cloud and Kubernetes infrastructure.
|
||||
I'm deeply passionate about open-source cloud-native solutions and actively engage in collaborative initiatives within this field.
|
||||
You can find my past speaking sessions on my [Sessionize](https://sessionize.com/maryamtavakkoli/) profile.
|
||||
Additionally, I regularly share my insights on new technologies through articles on my [Medium](https://medium.com/@maryam.tavakoli.3) account.
|
||||
As a CNCF ambassador, I contribute to organizing [Kubernetes and CNCF Finland Meetups](https://www.meetup.com/Kubernetes-Finland/),
|
||||
fostering knowledge exchange and community engagement.
|
||||
|
||||
!Maryam Tavakkoli](Images/day86.jpg)
|
||||
|
||||
## Description
|
||||
If you work with DevOps and Kubernetes, you know how important the command line interface (CLI) is for managing tasks.
|
||||
Fortunately, there are tools available that make the terminal easier to use in these environments.
|
||||
In this talk, we’ll explore some top tools that simplify your workflow and help you navigate the terminal with confidence in DevOps and Kubernetes.
|
||||
I have written an article with the same subject in the past that you can read on
|
||||
[Medium](https://medium.com/aws-tip/tools-to-make-your-terminal-devops-and-kubernetes-friendly-64d27a35bd3f).
|
||||
# Day 86 - Tools To Make Your Terminal DevOps and Kubernetes Friendly
|
||||
[](https://www.youtube.com/watch?v=QL7h9J5Eqd8)
|
||||
|
||||
various tools that can help developers manage Kubernetes effectively. Here is a summary of the tools mentioned:
|
||||
|
||||
1. Alias for kubectl (e.g., 'K'): Shortens kubectl commands, making it quicker and easier to use.
|
||||
2. PS1: Prevents errors by showing which cluster and namespace you are currently working on in your terminal.
|
||||
3. CBE color: Enhances the output of kubernetes commands with colors for improved visibility.
|
||||
4. Cube CTX and Cube NS: Allows users to switch between different contexts and namespaces in a Kubernetes system.
|
||||
5. K9: A user-friendly command-line tool that provides a visual dashboard for managing Kubernetes clusters.
|
||||
6. Kubernetes Lens: A desktop application with a graphical interface for managing and monitoring Kubernetes clusters.
|
||||
7. Popy: Analyzes a Kubernetes cluster to identify potential issues, best practices violations, resource inefficiencies, and security concerns.
|
||||
8. Cube capacity: Provides insights into resource usage and capacity of your cluster, including CPU and memory requests and limits.
|
||||
9. Cube shell: Integrated shell for kubernetes CLI that suggests possible commands and provides visualization.
|
||||
|
||||
These tools can help developers improve productivity, reduce errors, and streamline Kubernetes management tasks. If you have any questions or would like to know more about these tools, feel free to reach out on LinkedIn or find the speaker's technical articles on Medium.
|
||||
**IDENTITY and PURPOSE**
|
||||
|
||||
As an expert content summarizer, I've taken on the task of condensing this session into a concise summary. Here's what I've found:
|
||||
|
||||
The session focuses on various tools for DevOps professionals, particularly those working with Terraform (TF), Kubernetes, and Git.
|
||||
|
||||
**Terraform Tools**
|
||||
|
||||
1. **TFC (Terraform Security Scanning)**: A security scanning tool designed specifically for Terraform code, identifying potential vulnerabilities and suggesting improvements.
|
||||
2. **Cube CTX**: Allows users to switch between different contexts in their system.
|
||||
3. **Cube NS**: Enables switching between different name spaces.
|
||||
|
||||
**Kubernetes Tools**
|
||||
|
||||
1. **K9**: A user-friendly command-line tool providing a visual dashboard for managing Kubernetes clusters.
|
||||
2. **Kubernetes Lens**: A desktop application offering a graphical interface for monitoring and managing clusters.
|
||||
3. **popy**: Analyzes Kubernetes cluster resource usage, identifying potential issues, misconfigurations, or security concerns.
|
||||
|
||||
**Git Tools**
|
||||
|
||||
1. **q PS1**: A helpful tool that visually displays the current Kubernetes context and namespace, preventing errors.
|
||||
|
||||
The session concludes by emphasizing the importance of using these tools to boost productivity and make life easier for DevOps professionals.
|
||||
|
||||
That's it! If you have any questions or would like to learn more about these tools, feel free to reach out to me on LinkedIn or Medium.
|
||||
|
||||
351
2024/day87.md
@ -1,338 +1,39 @@
|
||||
## Hands-on Performance Testing with k6
|
||||
# Day 87 - Hands-on Performance Testing with k6
|
||||
[](https://www.youtube.com/watch?v=Jg4GRzRHX9M)
|
||||
|
||||
Performance testing is the testing practice that involves verifying how the system behaves and performs, often regarding speed and reliability.
|
||||
The session covers (k6) which collects both built-in and custom metrics. The built-in metrics include:
|
||||
|
||||
But let's start with one of the common questions. What is the difference between performance and load testing, and what types of tests exist? Some authors have minor differences in their definitions and categorizations. **Performance testing** and **load testing** are often used interchangeably, referring to the same concept.
|
||||
1. Current/Active Virtual Users: The current number of active virtual users in the test.
|
||||
2. Iteration Information: Information about the iteration such as the type.
|
||||
3. HTTP Request Metrics (Rate Metric): Information about the HTTP requests, including the request rate and response time (time spend on the request excluding the connection time).
|
||||
4. Other HTTP Request Metrics (Red Metric): Information about percentiles of the HTTP requests collected from all data points and giving a percent statistic. Other counter metrics like HTTP Rex give real-time data on the terminal.
|
||||
|
||||
Performance testing is the umbrella term. Load tests are performance tests that inject 'load' over a period, typically simulated through concurrent users or requests per second.
|
||||
Custom metrics are those that you define in your test using the k6 module with the type of metric set as either Trend or Counter. For example, in quick pix sample number four, we defined a custom metric 'pixza have more than six ingredient' using the check API to verify a condition and as many checks as desired can be added for any request or object.
|
||||
|
||||
Given the type of load and their purpose, we find the common load test types:
|
||||
- **Smoke tests**: minimal load.
|
||||
- **Average-load tests**: load with usual traffic.
|
||||
- **Stress tests**: load exceeding the usual traffic.
|
||||
- **Spike tests**: a short peak of load.
|
||||
- **Soak tests**: load for an extended period.
|
||||
- **Breakpoint tests**: gradual increase of load to find the system's limits.
|
||||
- **Scalability tests**: load to verify scalability and elasticity policies.
|
||||
Assertions in K6 can be defined using either the check API or the StresScore API. Checks don't make the test fail even if they do, but you can use StresScore to define the pass/fail criteria of your test based on Casic metrics. In the example provided, a stress test was defined to specify that only 1% of HTTP requests should fail and that 95% of the request should be below half a second and 99% of the request should be below 1 second for response times, while also setting a threshold based on the custom metric (average should be below two). If this condition fails, the test will report a failure and an informative message.
|
||||
|
||||
Performance tests that run on a single thread include **browser performance tests** and **synthetic tests**, often called synthetic monitoring. Additionally, among others, there are tests designed for measuring the execution time of specific code (**performance profiling**) or service time in distributed systems.
|
||||
You can learn more about K6's features, testing guides, and extensions from the Casic documentation. There are also many community-built extensions available to help with specific use cases.
|
||||
**IDENTITY and PURPOSE**
|
||||
|
||||
**Custom Metrics and Purposes**
|
||||
|
||||
### Non-scriptable vs Scriptable tools
|
||||
* Custom metrics can be defined using the `counter` and `trend` types.
|
||||
* An example of a custom metric is tracking the number of pixels (Quick Pixa) and ingredients returned in a test.
|
||||
* The purpose of these metrics is to gain insights into system behavior, identify trends, and optimize performance.
|
||||
|
||||
If you are looking to create a performance test with load — let's just call it a load test ;) — two types of tools are at your disposal. Non-scriptable tools generate the load test based on one or multiple requests, perfect for simple scenarios. Scriptable tools, on the other hand, provide a wider range of functionalities and allow you to implement a script to simulate more realistic scenarios.
|
||||
**End-of-Test Results**
|
||||
|
||||
There are dozens of load testing tools available. Some of the most popular ones are:
|
||||
- **Non-scriptable tools**: [ab](https://httpd.apache.org/docs/2.4/programs/ab.html), [hey](https://github.com/rakyll/hey), [vegeta](https://github.com/tsenart/vegeta), [siege](https://github.com/JoeDog/siege).
|
||||
* K6 provides three options for displaying end-of-test results: terminal output, CSV files, and custom summaries.
|
||||
* Custom summaries allow users to customize the format and content of the test results.
|
||||
|
||||
- **Scriptable tools**: [Gatling (Scala)](https://gatling.io/), [k6 (Javascript/Go)](https://k6.io/), [Locust (Python)](https://locust.io/).
|
||||
**Real-time Data Collection and Visualization**
|
||||
|
||||
[Wrk](https://github.com/wg/wrk) and [Artillery](https://www.artillery.io/) fall somewhere in the middle and worth a mention; wrk accepts LuaJIT scripts, and Artillery instructions are written in YAML files, similar to [Drill](https://github.com/fcsonline/drill). Another category is UI-based tools, which includes popular ones such as [Postman](https://www.postman.com/) and [JMeter](https://jmeter.apache.org/). We also find benchmarking tools designed for specific protocols, like [ghz(gRPC)](https://ghz.sh/), [HammerDB(SQL DBs)](https://www.hammerdb.com/), [AMQP Benchmark](https://github.com/chirino/amqp-benchmark), and many more.
|
||||
* K6 provides real-time data collection capabilities through its Output module.
|
||||
* This allows users to send data points to various destinations, such as Prometheus or Grafana.
|
||||
* These tools enable visualization and monitoring of system performance in real-time.
|
||||
|
||||
Typically, non-scriptable tools are designed to set the load by specifying a request rate. In our first example, we aim to test how the [https://httpbin.org/get](https://httpbin.org/get) endpoint performs under a load of 20 requests per second for 30 seconds. With [Vegeta](https://github.com/tsenart/vegeta), we would run the following command:
|
||||
**Assertions and Thresholds**
|
||||
|
||||
```bash
|
||||
echo "GET https://httpbin.org/get" | vegeta attack -duration=30s -rate=20 | vegeta report
|
||||
```
|
||||
|
||||
In the other category, scriptable tools are designed to also set the load by specifying a number of concurrent users, also known as virtual users. For this tutorial, we’ll use [k6](https://k6.io/), an extensible open-source performance testing tool that is written in Go and scriptable in Javascript.
|
||||
|
||||
### Run a simple k6 test
|
||||
|
||||
For learning purposes, let’s create a simple k6 script to test the previous endpoint with 10 concurrent users. When testing with concurrent users, it is recommended to add pauses between user actions, just like real users interact with our apps. In the following test, each user will wait for one second after the endpoint responds.
|
||||
|
||||
```javascript
|
||||
// script.js
|
||||
|
||||
import http from 'k6/http';
|
||||
import { sleep } from 'k6';
|
||||
|
||||
export const options = {
|
||||
vus: 10, // virtual users
|
||||
duration: '30s', // total test duration
|
||||
};
|
||||
|
||||
export default function () {
|
||||
http.get('https://httpbin.org/get');
|
||||
|
||||
// pause for 1 second
|
||||
sleep(1);
|
||||
}
|
||||
```
|
||||
|
||||
Run the script with the following command:
|
||||
|
||||
```bash
|
||||
k6 run script.js
|
||||
```
|
||||
|
||||
By default, k6 outputs the test results to `stdout`. We’ll see test results later.
|
||||
|
||||
|
||||
### Model the test load (workload)
|
||||
|
||||
Scriptable tools offer more flexibility to model the workload than non-scriptable tools.
|
||||
|
||||
Two concepts are key to understanding how to model the load in k6: Virtual Users (VUs) and iterations. A Virtual User is essentially a thread that executes your function, while an iteration refers to one complete execution of that function.
|
||||
|
||||
k6 acts as a scheduler of VUs and iterations based on the test load configuration, providing multiple options for configuring the test load:
|
||||
|
||||
**(1) [vus](https://grafana.com/docs/k6/latest/using-k6/k6-options/reference/#vus) and [iterations](https://grafana.com/docs/k6/latest/using-k6/k6-options/reference/#iterations)**: specifying the number of virtual users and total number of executions of the default function.
|
||||
|
||||
In the following example, k6 schedules 10 virtual users that will execute the default function 30 times in total (between all VUs).
|
||||
|
||||
```javascript
|
||||
export const options = {
|
||||
iterations: 30, // the total number of executions of the default function
|
||||
vus: 10, // 10 virtual users
|
||||
};
|
||||
```
|
||||
|
||||
Replace the options settings in the previous script and run the test again.
|
||||
|
||||
**(2) [vus](https://grafana.com/docs/k6/latest/using-k6/k6-options/reference/#vus) and [duration](https://grafana.com/docs/k6/latest/using-k6/k6-options/reference/#duration)**: specifying the number of virtual users and the total test duration.
|
||||
|
||||
```javascript
|
||||
export const options = {
|
||||
vus: 10, // virtual users
|
||||
duration: '30s', // total test duration
|
||||
};
|
||||
```
|
||||
|
||||
In the following example, k6 schedules 10 virtual users that will execute the default function continuously during 30 seconds.
|
||||
|
||||
Replace the options settings in the previous script and run the test again.
|
||||
|
||||
**(3) [stages](https://grafana.com/docs/k6/latest/using-k6/k6-options/reference/#stages)**: specifying a list of periods that must reach a specific VU target.
|
||||
|
||||
```javascript
|
||||
export const options = {
|
||||
stages: [
|
||||
// ramp up from 0 to 20 VUs over the next 20 seconds
|
||||
{ duration: '20s', target: 20 },
|
||||
// run 20 VUs over the next minute
|
||||
{ duration: '1m', target: 20 },
|
||||
// ramp down from 20 to 0 VUs over the next 20 seconds
|
||||
{ duration: '20s', target: 0 },
|
||||
],
|
||||
};
|
||||
```
|
||||
|
||||
Replace the options settings in the previous script and run the test again.
|
||||
|
||||
**(4) [Scenarios](https://grafana.com/docs/k6/latest/using-k6/scenarios/)**: provide more options to model the workload and the capability to execute multiple functions, each with distinct workloads.
|
||||
|
||||
This tutorial cannot cover all the different scenario options, so please refer to the [Scenario documentation for further details](https://grafana.com/docs/k6/latest/using-k6/scenarios/). However, we’ll use scenarios to demonstrate an example that sets the load in terms of requests per second—20 requests per second for 30 seconds like the previous Vegeta example.
|
||||
|
||||
```javascript
|
||||
import http from 'k6/http';
|
||||
|
||||
export const options = {
|
||||
scenarios: {
|
||||
default: {
|
||||
executor: 'constant-arrival-rate',
|
||||
|
||||
// How long the test lasts
|
||||
duration: '30s',
|
||||
|
||||
// Iterations rate. By default, the `timeUnit` rate is 1s.
|
||||
rate: 20,
|
||||
|
||||
|
||||
// Required. The value can be the same as the rate.
|
||||
// k6 warns during execution if more VUs are needed.
|
||||
preAllocatedVUs: 20,
|
||||
},
|
||||
},
|
||||
};
|
||||
|
||||
export default function () {
|
||||
http.get('https://httpbin.org/get');
|
||||
}
|
||||
```
|
||||
|
||||
This test uses the [`constant-arrival-rate` scenario](https://grafana.com/docs/k6/latest/using-k6/scenarios/executors/constant-arrival-rate/) to schedule a rate of iterations, telling k6 to schedule the execution of 20 iterations (`rate`: 20) per second (the default `timeUnit`).
|
||||
|
||||
Given that each iteration executes only one request, the test will run 20 requests per second. Mathematically speaking:
|
||||
- 20 requests per second = 20 iterations per second x 1 request per iteration
|
||||
|
||||
Now, run this test using the `k6 run` command. You can see the test request rate by looking at the `http_reqs` metric, which reports the number of http requests and its request rate. In our example, it is close to our goal of 20 requests per second.
|
||||
|
||||
```bash
|
||||
http_reqs......................: 601 19.869526/s
|
||||
```
|
||||
|
||||
|
||||
### Performance test results
|
||||
|
||||
After running the test, it’s common to assess how well your system handled the traffic. Typically, you can examine the test result data in two places: either from your testing tool or from your observability/monitoring solution.
|
||||
|
||||
Performance testing tools report the response times (latency) and response errors (failures) during the test. This data can indicate whether the system is struggling or failing to handle the traffic, but it won’t tell you what issues are happening in the system. For root-cause analysis, turn to your observability solution to understand what’s happening internally.
|
||||
|
||||
In this section, we cover the fundamentals aspects of k6 metrics and an overview of the various test result options. Basically, during test execution, k6 collects time-series data for built-in and custom metrics and these can be exported in different ways for further analysis.
|
||||
|
||||
Let’s start enumerating a few important metrics that k6 collects by default, also known as [built-in k6 metrics](https://grafana.com/docs/k6/latest/using-k6/metrics/reference/):
|
||||
- `http_reqs`, to measure the number of requests (request rate).
|
||||
- `http_req_failed`, to measure the error rate (errors).
|
||||
- `http_req_duration`, to measure response times (latency).
|
||||
- `vus`, to measure the number of virtual users (traffic).
|
||||
|
||||
k6 provides other [built-in k6 metrics](https://grafana.com/docs/k6/latest/using-k6/metrics/reference/) dependent on the [k6 APIs](https://grafana.com/docs/k6/latest/javascript-api/) used in your script, including other HTTP, gRPC, Websocket, or Browser metrics. After completing the test run, k6 outputs the aggregated results of the metrics to `stdout`.
|
||||
|
||||
```bash
|
||||
data_received..................: 490 kB 16 kB/s
|
||||
data_sent......................: 49 kB 1.6 kB/s
|
||||
http_req_blocked...............: avg=30ms min=1µs med=2µs max=565.41ms p(90)=4µs p(95)=425.64ms
|
||||
http_req_connecting............: avg=9.34ms min=0s med=0s max=173.06ms p(90)=0s p(95)=130.03ms
|
||||
http_req_duration..............: avg=189.53ms min=126.01ms med=158.87ms max=1.21s p(90)=209.95ms p(95)=372.09ms
|
||||
{ expected_response:true }...: avg=189.53ms min=126.01ms med=158.87ms max=1.21s p(90)=209.95ms p(95)=372.09ms
|
||||
http_req_failed................: 0.00% ✓ 0 ✗ 600
|
||||
http_req_receiving.............: avg=518.35µs min=22µs med=173µs max=23.02ms p(90)=300.1µs p(95)=759.39µs
|
||||
http_req_sending...............: avg=480.17µs min=96µs med=397µs max=7.45ms p(90)=627.4µs p(95)=1.02ms
|
||||
http_req_tls_handshaking.......: avg=20.35ms min=0s med=0s max=337.45ms p(90)=0s p(95)=292.16ms
|
||||
http_req_waiting...............: avg=188.53ms min=123.86ms med=158.04ms max=1.21s p(90)=209.46ms p(95)=371.52ms
|
||||
http_reqs......................: 600 19.926569/s
|
||||
iteration_duration.............: avg=219.99ms min=126.44ms med=161.65ms max=1.21s p(90)=449.25ms p(95)=611.17ms
|
||||
iterations.....................: 600 19.926569/s
|
||||
vus............................: 3 min=3 max=12
|
||||
vus_max........................: 40 min=40 max=40
|
||||
```
|
||||
|
||||
However, aggregated results hide a lot of information. It is more useful to visualize time-series graphs to understand what happened at different stages of the test.
|
||||
|
||||
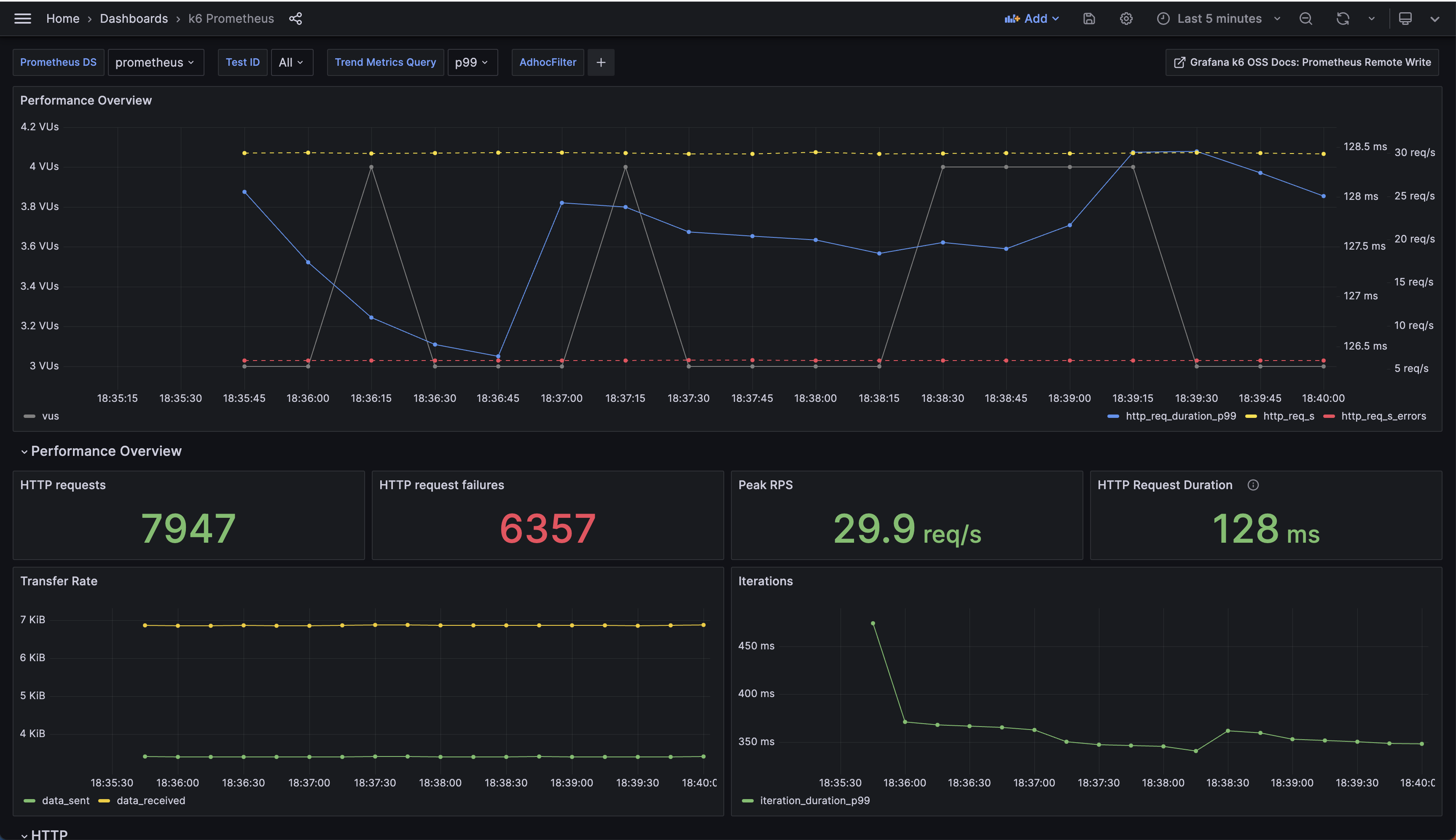
|
||||
|
||||
|
||||
What options do we have for visualizing time-series results? With k6, you can send the time-series data of all the k6 metrics to any backend. k6 provides a few options, others are available through output extensions, and you also have the option to implement your custom output.
|
||||
|
||||
To learn about all the available options, refer to the [k6 real time output documentation](https://grafana.com/docs/k6/latest/results-output/real-time/).
|
||||
|
||||
#### Store results in Prometheus and visualize with Grafana
|
||||
|
||||
If you want to send [k6 time-series data to a Prometheus instance](https://grafana.com/docs/k6/latest/results-output/real-time/prometheus-remote-write/) as part of this tutorial, try using the [QuickPizza Demo](https://github.com/grafana/quickpizza#local-setup) with Docker compose. It runs a simple web app and, optionally, a Prometheus instance.
|
||||
|
||||
```bash
|
||||
git clone git@github.com:grafana/quickpizza.git
|
||||
cd quickpizza
|
||||
docker compose -f docker-compose-local.yaml up -d
|
||||
```
|
||||
|
||||
Visit QuickPizza at [localhost:3333](http://localhost:3333/), the Grafana instance at [localhost:3000](http://localhost:3000/), and the Prometheus instance at [localhost:9090](https://localhost:9090).
|
||||
|
||||
Now, let’s run a test and stream k6 metrics as time-series data to our local Prometheus instance using the [`--out`](https://grafana.com/docs/k6/latest/using-k6/k6-options/reference/#results-output) option. Run either the previous test or one of the examples in the QuickPizza repository:
|
||||
|
||||
```bash
|
||||
k6 run -o experimental-prometheus-rw script.js
|
||||
|
||||
# or
|
||||
|
||||
k6 run -o experimental-prometheus-rw k6/foundations/01.basic.js
|
||||
```
|
||||
|
||||
To visualize the performance results, visit the Grafana instance([localhost:3000](http://localhost:3000/)) and select the `k6 Prometheus` dashboard. You can also query k6 metrics from the Prometheus web UI or by using [Grafana Explore](https://grafana.com/docs/grafana/latest/explore/).
|
||||
|
||||
For in-depth overview about the various options shown in this section, refer to the following resources:
|
||||
|
||||
- [k6 results output documentation](https://grafana.com/docs/k6/latest/results-output/)
|
||||
- [Ways to visualize k6 results](https://k6.io/blog/ways-to-visualize-k6-results/)
|
||||
|
||||
|
||||
### Define Pass/Fail criteria in k6 tests
|
||||
|
||||
In testing, an assertion typically refers to verifying a particular condition in the test: Is this true or false? For most testing tools, if an assertion evaluates as false, the test fails.
|
||||
|
||||
k6 works slightly different in this regard, having two different APIs for defining assertions:
|
||||
|
||||
1. [Thresholds](https://grafana.com/docs/k6/latest/using-k6/thresholds/): used to establish the Pass/Fail criteria of the test.
|
||||
2. [Checks](https://grafana.com/docs/k6/latest/using-k6/checks/): used to create assertions and inform about their status without affecting the Pass/Fail outcome.
|
||||
|
||||
Most of the testing tools provide an API to assert boolean conditions. k6 provides [checks](https://grafana.com/docs/k6/latest/using-k6/checks/) to validate boolean conditions in our tests, similar to assertions in other testing frameworks.
|
||||
|
||||
```javascript
|
||||
check(res, {
|
||||
"status is 200": (res) => res.status === 200,
|
||||
"body includes URL": (res) => res.body.includes("https://httpbin.org/get"),
|
||||
});
|
||||
```
|
||||
|
||||
Why doesn't a test fail due to a check failure? It’s a design choice. Production systems typically don’t aim for 100% reliability; instead, we define error budgets and 'nines of availability,' accepting a certain percentage of errors.
|
||||
|
||||
Some failures are expected 'Under Load'. A regular load test can evaluate thousands or millions of assertions; thus, by default, k6 won’t fail a test due to check failures.
|
||||
|
||||
Now, practice adding some checks to one of the previous tests. When the test ends, k6 prints the check results to the terminal:
|
||||
|
||||
```diff
|
||||
+ ✓ status is 200
|
||||
+ ✓ body includes URL
|
||||
```
|
||||
|
||||
The other API is [Thresholds](https://grafana.com/docs/k6/latest/using-k6/thresholds/), specifically designed to set Pass/Fail criteria in our tests. Let’s define the success criteria of the test based on two of the golden signals: latency and errors:
|
||||
|
||||
- 95% of requests must have a latency below 600ms.
|
||||
- Less than 0.5% of requests must respond with errors.
|
||||
|
||||
Thresholds evaluate the Pass/Fail criteria by querying k6 metrics using stats functions. Earlier, we reviewed the k6 metrics for latency and errors:
|
||||
- `http_req_duration`, to measure response times (latency).
|
||||
- `http_req_failed`, to measure the error rate (errors).
|
||||
|
||||
The previous Pass/Fail criteria can be added to the `options` object as follows:
|
||||
|
||||
```javascript
|
||||
export const options = {
|
||||
....
|
||||
thresholds: {
|
||||
http_req_duration: ['p(95)<600'],
|
||||
http_req_failed: ['rate<0.005'],
|
||||
},
|
||||
};
|
||||
```
|
||||
|
||||
|
||||
Add these thresholds to the previous test and run the test again.
|
||||
|
||||
When the test ends, k6 reports the threshold status with a green checkmark ✅ or red cross ❌ near the metric name.
|
||||
|
||||
```bash
|
||||
...
|
||||
✓ http_req_duration..............: avg=106.24ms min=103.11ms....
|
||||
✓ http_req_failed................: 0.00% ✓ 0 ✗ 9
|
||||
...
|
||||
default ✓ [======================================] 1 VUs 10s
|
||||
```
|
||||
|
||||
When the test fails, k6 returns a non-zero error code, which is necessary when integrating on CI/CD pipelines. Now, please practice by changing the criteria and make the test fail. k6 will then report something similar to:
|
||||
|
||||
```bash
|
||||
...
|
||||
✗ http_req_duration..............: avg=106.24ms min=103.11ms....
|
||||
✓ http_req_failed................: 0.00% ✓ 0 ✗ 9
|
||||
...
|
||||
default ✓ [======================================] 1 VUs 10s
|
||||
ERRO[0011] thresholds on metrics 'http_req_duration' have been crossed
|
||||
```
|
||||
|
||||
Thresholds are very flexible, allowing various cases such as:
|
||||
|
||||
|
||||
|
||||
- Defining thresholds on [custom metrics](https://grafana.com/docs/k6/latest/using-k6/metrics/create-custom-metrics/).
|
||||
- Setting multiple thresholds for the same metric.
|
||||
- Querying [tags](https://grafana.com/docs/k6/latest/using-k6/tags-and-groups/#tags) in metrics.
|
||||
- Aborting the test when threshold is breached.
|
||||
|
||||
For further details and examples, please refer to the [Thresholds documentation](https://grafana.com/docs/k6/latest/using-k6/thresholds/).
|
||||
|
||||
|
||||
### Wrapping up
|
||||
|
||||
This tutorial aimed to provide a practical foundation in performance testing, particularly in the use of k6. Through hands-on examples, we delved into k6's capabilities, including modeling workload, analyzing results, and establishing Pass/Fail criteria to verify SLO compliance.
|
||||
|
||||
I encourage you to continue exploring the depths of this topic. But more importantly, **adopt a proactive approach in reliability testing and don’t wait to start until critical failures happen**. [Automating performance testing](https://grafana.com/docs/k6/latest/testing-guides/automated-performance-testing/) will help you in your reliability efforts.
|
||||
|
||||
Thank you for joining today! I hope you have learned something new and have sparked the curiosity in performance and reliability testing. For further resources, please visit:
|
||||
|
||||
- [k6 documentation](https://grafana.com/docs/k6/latest/)
|
||||
- [Load test types](https://grafana.com/docs/k6/latest/testing-guides/test-types/)
|
||||
- [QuickPizza Demo - k6 Testing environment](https://github.com/grafana/quickpizza)
|
||||
- [k6-awesome](https://github.com/grafana/awesome-k6)
|
||||
- [How they load](https://github.com/aliesbelik/how-they-load)
|
||||
* Assertions are used to define pass/fail criteria for test results.
|
||||
* Two types of assertions are available: `check` and `stress`.
|
||||
* Stress assertions allow users to set custom failure thresholds based on specific metrics or conditions.
|
||||
|
||||
@ -0,0 +1,31 @@
|
||||
# Day 88 - What Developers Want from Internal Developer Portals
|
||||
[](https://www.youtube.com/watch?v=Qo9D8U8ZmS0)
|
||||
|
||||
A session on Cortex, an IDP (Identity and Developer Portal) solution that offers a unique plugin system for customization, along with its adoption strategies. Here's a summary:
|
||||
|
||||
1. Cortex provides pre-built Integrations and a self-service platform out of the box. However, it also encourages users to build their own plugins to accommodate their organization's specific needs using React TypeScript. These plugins can be embedded across various pages, allowing for custom features like building your release management UI or a single portal for C Kubernetes control plane.
|
||||
|
||||
2. To successfully adopt IDPs like Cortex, organizations should focus on collecting information about existing services, infrastructure, accountability, and interaction points. This will help optimize and build better experiences.
|
||||
|
||||
3. Set a North Star to define where the organization is today and where it aims to be across various pillars such as production readiness standards, service maturity, reliability, security, and productivity standards. Assess the baseline to measure impact and prioritize action for developers accordingly.
|
||||
|
||||
4. Enable and optimize experiences based on the data collected. For instance, if you find friction in specific areas like setting up SLOs or spinning up infrastructure, you can provide self-serve experiences tailored to those problems. Continuously measure, assess, and make changes to create a feedback loop that drives adoption, value, and productivity.
|
||||
|
||||
5. Ganesh, the co-founder & CTO of Cortex, is available for questions via email on his LinkedIn profile. His email address is [Ganesh@cortex](mailto:Ganesh@cortex).
|
||||
|
||||
Hope this summary helps! Let me know if you need further clarification.
|
||||
The current state of your business, organization, and engine - that's what's most important when it comes to scoring drives action for developers and giving them clear visibility into what they should be working on.
|
||||
|
||||
A developer portal must provide an out-of-the-box reporting capability to give leadership visibility into the organization, services, and infrastructure. This will enable data-driven decisions without which you're not solving for a key persona (leadership) that cares about the catalog but in a different way.
|
||||
|
||||
Self-service is another crucial aspect of a developer portal. You can spin up new services from scratch using a scaffolder or template, giving developers golden paths to create consistent and standardized code. This also enables a feedback loop within your developer portal that says "here's what good is; here's how you can go and do that really easily".
|
||||
|
||||
Actions are the ability to trigger events outside of the system, allowing developers to build payloads and give them simple form UIs to trigger external systems.
|
||||
|
||||
Lastly, plugins - a unique feature in cortex - allows you to build your own capabilities on top of the platform. You can create your own react typescript plugins and embed them inside cortex, giving you flexibility and the ability to build custom experiences for developers.
|
||||
|
||||
So, how do successful organizations adopt IDPs? They start by collecting information about what services are out there, who owns what, and how they all interact with each other. Once you have that information, you set a North star - where are we today, where are we trying to get to, and prioritize action for your developers.
|
||||
|
||||
The outcome of this is enabling and optimizing experiences that drive impact. By creating personalized experiences, automating things away, and building custom dashboards, you can optimize the experience for developers and create a feedback loop that drives adoption and value.
|
||||
|
||||
That's how organizations adopt IDPs successfully!
|
||||
@ -0,0 +1,37 @@
|
||||
# Day 89 - Seeding Infrastructures: Merging Terraform with Generative AI for Effortless DevOps Gardens
|
||||
[](https://www.youtube.com/watch?v=EpkYCmKtL6w)
|
||||
|
||||
Thank you for sharing your insights and case study! It seems that you have successfully implemented a generative AI-powered seating engine in a project aimed at building a rapidly growing website with scalable digital infrastructure. The benefits you mentioned, such as reduced downtime, cost savings, time savings, and enhanced user experience, are indeed valuable outcomes of automation using AI.
|
||||
|
||||
To summarize your key learnings:
|
||||
1. Automation's impact should not be underestimated, offering potential for significant cost and time savings.
|
||||
2. Security is crucial, requiring human oversight to validate recommendations and ensure best practices are followed.
|
||||
3. Predictive analytics will play a more significant role as AI generates valuable analysis and insights.
|
||||
4. Collaborative AI, where humans work with AI to monitor its output, will be increasingly important in the future.
|
||||
5. Resource optimization will become a prominent aspect of devops, with generative AI providing suggestions for improvements.
|
||||
6. Understanding generative AI is essential when creating your own seating engine.
|
||||
7. Human supervision and monitoring are still vital to ensure the output of AI aligns with human requirements and follows normal guidelines, particularly for security purposes.
|
||||
8. Don't cut corners; ensure that the entire process, including security measures, is in place and followed accordingly.
|
||||
|
||||
Overall, it was a fascinating session, and I appreciate your sharing valuable insights about the role of generative AI in devops. Your points about the importance of human oversight in an autonomous workload are especially important to remember, as AI should complement our work, not replace it. Thank you once again for this enlightening discussion, and feel free to connect with me on my socials if you have any questions or further insights!
|
||||
Here is a summarized version of the content:
|
||||
|
||||
**Identity and Purpose**
|
||||
|
||||
The speaker emphasized the importance of understanding generative AI in creating one's own seating engine. They highlighted that automation cannot be understated, as it can lead to significant cost savings and time savings.
|
||||
|
||||
**Case Study: Scalable Digital Infrastructure**
|
||||
|
||||
The speaker shared a case study on building a rapidly growing website needing scalable digital infrastructure. They used a seating engine to automate workflows, including adaptive scaling for traffic and form submission data. The result was a significant reduction in downtime maintenance costs and enhanced user experience.
|
||||
|
||||
**Key Learnings**
|
||||
|
||||
* Automation can lead to cost savings and time savings.
|
||||
* DevOps is evolving towards generative AI-driven practices.
|
||||
* Security is key and requires human oversight.
|
||||
* Autonomous devops will continue to gain popularity.
|
||||
* Predictive analytics, enhanced security, and resource optimization will be crucial aspects of future devops.
|
||||
|
||||
**Future of DevOps**
|
||||
|
||||
The speaker predicted that the future of devops will involve more autonomous workflows, predictive analytics, and collaborative AI. They emphasized the importance of humans working with AI to ensure that final outputs meet requirements.
|
||||
@ -0,0 +1,30 @@
|
||||
# Day 90 - Fighting fire with fire: Why we cannot always prevent technical issues with more tech
|
||||
[](https://www.youtube.com/watch?v=PJsBQGKkn60)
|
||||
|
||||
To summarize, the goal is to create effective documentation that empowers your team to respond effectively to various situations. You've identified two main types of documentation: developer documentation (internal team, focusing on tool usage and source code) and user documentation (external users, focusing on product usage).
|
||||
|
||||
In Car Engineering (CAR E), you want to document known knowns (things understood and aware of), known unknowns (issues understood but not yet fully comprehended), known unknowns (understood but not yet aware), and unknown unknowns (unknown and uncomprehended issues). To understand the current state of your infrastructure, map services dependencies (internal and external) and plan experiments with defined goals, components, expected results, and factors affecting your hypothesis.
|
||||
|
||||
Projects such as CNCF's Mesh and Litmos CS can help automate experiments and post-mortem reviews, which are crucial for learning from past incidents and improving future responses. Postmortems also serve as an opportunity to enhance documentation on incident resolution.
|
||||
|
||||
The key takeaway is to document your work consistently, whether you're working with your own infrastructure or that of an organization. Sharing your notes publicly can be beneficial to others who may join your team in the future. Remember, there's no right or wrong when it comes to writing—it's better to write things down incorrectly than for someone to try a command based on your past notes that no longer works.
|
||||
|
||||
Thank you for joining this presentation. For more content from me, visit an.com. Shout out to Michael, the organizer of 90 Days of DevOps, for having me here. I hope this was useful for you, and I look forward to seeing you on my YouTube channel and potentially at a conference in person. Have an amazing day!
|
||||
|
||||
**Whom are you writing for?**
|
||||
The audience for documentation can be developers (e.g., within a team or open-source project) or users (e.g., end-users of a service). When writing for developers, assume an existing knowledge level, while for users, provide more detailed explanations. Consider the stages when the product is supposed to be used (e.g., installation, upgrade, or use new features).
|
||||
|
||||
**What are the goals?**
|
||||
Documentation aims to reach specific goals, such as providing setup and configuration guides or describing implementation scenarios. Tutorials typically have a narrower scope, serving a specific use case.
|
||||
|
||||
**Technical Solutions:**
|
||||
The presentation mentions KGBT (Knowledge Graph-Based Tool) for scanning Kubernetes clusters and triaging issues. This tool helps enrich documentation with AI-powered insights. Other technical solutions include documentation frameworks like Diet Taco's framework, which models documentation after KGBT and Canonical's model.
|
||||
|
||||
**C Engineering Experiments:**
|
||||
In C engineering, there are known-knowns (things we're aware of and understand), known-unknowns (aware but don't understand), unknown-knowns (understand but not aware), and unknown-unknowns (neither aware nor understand). To gain an understanding of the current state of infrastructure, map services, dependencies, both internal and external.
|
||||
|
||||
**Post-Mortem Reviews:**
|
||||
After running experiments, conduct post-mortem reviews to understand which components have been tested and how to solve incidents in the future. This allows for sharing knowledge with others and enhancing documentation on resolving incidents.
|
||||
|
||||
**Main Tip:**
|
||||
The presenter's main tip is to start writing down what you're doing, whether working with your own home cluster or organization's infrastructure. Share notes publicly to help others and gain value from documenting experiences.
|
||||
27
2024/day91.md
Normal file
@ -0,0 +1,27 @@
|
||||
# Day91 - Team Topologies and Platform Engineering
|
||||
[](https://www.youtube.com/watch?v=XgXeuRBzGLc)
|
||||
|
||||
The text discusses four types of teams in an organization and their interaction with platform engineering, focusing on Team Topologies.
|
||||
|
||||
1. Workflow Teams: These are responsible for executing work as it comes in, handling exceptions, and ensuring that outputs meet expectations. They can also help to identify opportunities for automation or standardization.
|
||||
|
||||
2. Platform Teams: These teams create, maintain, and improve the technology platforms and tools that enable other teams to do their jobs effectively and efficiently. Platform teams are responsible for building a robust, reliable infrastructure that can support the organization's needs.
|
||||
|
||||
3. Conductor Teams (or Enabler Teams): These teams help workflow and platform teams by coordinating activities across the organization, removing obstacles, and ensuring that everyone has the resources they need to do their jobs effectively. They also play a crucial role in driving collaboration and communication between teams.
|
||||
|
||||
4. Community Teams: These teams support the broader community of practice within the organization, sharing knowledge, best practices, and fostering a culture of learning and continuous improvement.
|
||||
|
||||
The text suggests that for an organization to achieve fast flow (efficient, effective work), it's essential to have the right team structures and interactions. It also emphasizes that these structures are not static but evolve over time as the organization matures. The text introduces DDD (Domain-Driven Design) as a toolbox of methodologies to help organizations structure their teams based on logical business and technical domains, influencing the software they develop.
|
||||
|
||||
The text briefly mentions the Independent Service Juristic methodology for discovering rough boundaries between teams by considering whether a component or interaction could be offered as a standalone SaaS service. It's important to note that this is just one methodology among many and that organizing for fast flow means constantly adjusting and trending in the right direction, rather than striving for perfection at any given moment.
|
||||
|
||||
The text concludes by inviting the audience to reach out if they have further questions and offering workshops and trainings on related topics such as team topologies, creativity, and data engineering.
|
||||
This text discusses the concept of platform teams, which are groups of experts that provide standardized components for other teams to use. These components can include cloud infrastructure, container platforms, virtual machines, networking, storage, load balancing, monitoring, identity and access management, CI/CD, databases, and more.
|
||||
|
||||
The key value that these platform teams provide is that they take care of the technical complexity needed to deliver software, allowing other teams to focus on solving business problems. This reduces cognitive load and increases autonomy for those teams.
|
||||
|
||||
The text also touches on the concept of "slowification," which involves temporarily slowing down or stopping to sharpen skills and solve a particular problem. This idea is inspired by the book "Wiring the Winning Organization."
|
||||
|
||||
Finally, the text discusses how team structures and responsibilities must evolve over time as an organization grows and matures. It mentions the independent service bus methodology for discovering rough boundaries between teams and provides a brief overview of domain-driven design (DDD) as a tool for coping with changing dynamics.
|
||||
|
||||
Overall, this text emphasizes the importance of platform teams in reducing technical complexity and increasing autonomy for other teams, while also highlighting the need for organizations to evolve their team structures and responsibilities over time.
|
||||
BIN
2024/thumbnails/day1.png
Executable file
{kind=link}
|
After Width: | Height: | Size: 729 KiB |
BIN
2024/thumbnails/day10.png
Executable file
{kind=link}
|
After Width: | Height: | Size: 778 KiB |
BIN
2024/thumbnails/day11.png
Executable file
{kind=link}
|
After Width: | Height: | Size: 758 KiB |
BIN
2024/thumbnails/day12.png
Executable file
{kind=link}
|
After Width: | Height: | Size: 753 KiB |
BIN
2024/thumbnails/day13.png
Executable file
{kind=link}
|
After Width: | Height: | Size: 782 KiB |
BIN
2024/thumbnails/day14.png
Executable file
{kind=link}
|
After Width: | Height: | Size: 763 KiB |
BIN
2024/thumbnails/day15.png
Executable file
{kind=link}
|
After Width: | Height: | Size: 768 KiB |
BIN
2024/thumbnails/day16.png
Executable file
{kind=link}
|
After Width: | Height: | Size: 767 KiB |
BIN
2024/thumbnails/day17.png
Executable file
{kind=link}
|
After Width: | Height: | Size: 755 KiB |
BIN
2024/thumbnails/day18.png
Executable file
{kind=link}
|
After Width: | Height: | Size: 782 KiB |
BIN
2024/thumbnails/day19.png
Executable file
{kind=link}
|
After Width: | Height: | Size: 756 KiB |